
تشخیص اشیا با پایتورچ
در این پست میخواهیم یک پروژه تشخیص اشیا با پایتورچ انجام دهیم. ما یک پروژه آبجکت دیتکشن نسبتا ساده انتخاب کردهایم. پایگاه دادهای که انتخاب شده شامل یک آبجکت (راکون) است. در این پروژه از شبکه Faster RCNN برای پیدا کردن راکون در تصویر استفاده شده است. کدهای پایتورچِ پروژه آبجکت دیتکشن به صورت خط به خط توضیح داده شدهاند. در این پست، نکات مهمی مانند نحوه نوشتن custom dataset در پایتورچ و … بررسی شده است. با هوسم همراه باشید …
تشخیص اشیا یعنی چه
به الگوریتمهایی که آبجکتها یا اشیا را در تصاویر مشخص میکنند، الگوریتمهای تشخیص اشیا یا object detection گفته میشود. اما این اشیا چگونه مشخص میشوند؟ در تشخیص اشیا یک باکس دور هر آبجکت یا شیء که در تصویر هست باید فیت شود. علاوه بر این باید برچسب هر آبجکت نیز مشخص شود. یعنی باید مشخص شود که آبجکت از چه کلاسی است.
پس ما از یک الگوریتم تشخیص اشیا دو چیز میخواهیم: 1- باندینگ باکسها برای هر آبجکت 2- کلاس هر آبجکت. در شکل زیر خروجی یک شبکه آبجکت دیتکشن نمایش داده شده است:

در پست « تشخیص اشیا با پایتورچ » میخواهیم یک پروژه تشخیص اشیا انجام دهیم. پروژهای که انتخاب کردیم، بسیار ساده است و تنها یک آبجکت دارد. در بخش بعد این پروژه شرح داده شده شده است …
هدف از انجام پروژه تشخیص اشیا با پایتورچ
همانطور که در بخشهای قبل هم گفتیم، پروژهای که انتخاب کردیم یک پروژه ساده آبجکت دیتکشن است. در این پروژه ما یک دیتاست کوچک شامل 200 تصویر انتخاب کردیم. تمامی تصاویر از راکونها هستند و در اکثر آنها تنها یک آبجکت وجود دارد. این تصاویر از اینترنت جمعآوری شده و برچسب زده شدهاند. اما از آنجایی که برچسب زدن تصاویر مبحث مهمی است، ما نحوه برچسب زدن تصاویر را نیز آموزش خواهیم داد.
شبکه های object detection متعددی وجود دارند. ما از شبکه Faster RCNN در پایتورچ استفاده خواهیم کرد. backbone شبکه Faster RCNN ما ResNet50 خواهد بود. همچنین ما از مدل آماده شبکه Faster RCNN در پایتورچ با وزنهای دیتاست COCO استفاده خواهیم کرد. هدف ما در این پروژه این است که شبکه Faster RCNN ResNet50 با وزنهای اولیه COCO را روی پایگاه داده خودمان آموزش دهیم. یعنی شبکه ما باید بتواند یک باندینگ باکس دور راکونها بکشد! بلوکدیاگرامِ پروژهای که میخواهیم انجام دهیم در شکل زیر آورده شده است:

معرفی پایگاه داده
گفتیم در پروژهای که سعی در انجامش داریم، میخواهیم راکونها را شناسایی کنیم! بنابراین به یک پایگاه داده متشکل از تصاویر راکونها نیاز داریم. پایگاه دادهای که انتخاب کردیم در این گیتهاب رپو وجود دارد. همه تصاویر این پایگاه داده از طریق سرچ گوگل و سایت Pixabay تهیه شده اند.
در پایگاه داده Raccoon Dataset تعداد 200 تصویر وجود دارد. برای هر تصویر در این پایگاه داده برچسب هم وجود دارد. یک نمونه تصویر به همراه برچسب آن در شکل زیر آورده شده است:

اگرچه پایگاه دادهای که ما انتخاب کردیم، برچسب دارد. اما ممکن است شما تصاویری داشته باشید که برچسب ندارند. مثلا بخواهید تصاویر بیشتری از راکونها پیدا کرده و پایگاه داده را بزرگتر کنید. در بخش بعدی روشهای برچسب زنی برای دادههای آبجکت دیتکشن را بررسی خواهیم کرد. برویم سراغ بخش بعدی …
ابزارهای برچسب زدن
یکی از راههایی که برای برچسب زدن دادههای آبجکت دیتکشن وجود دارد، نوشتن یک کد ساده است. شما میتوانید این کد را با هر زبان برنامهنویسی که دوست دارید بنویسید. اما در این قسمت یک نکته مهم وجود دارد که میتواند به کار شما سرعت ببخشد. ابزارهایی وجود دارند که کار برچسب زدن دادههای آبجکت دیتکشن را میتوان به وسیله آنها انجام داد. این ابزارها میتوانند آنلاین یا آفلاین باشند.
شما به وسیله این ابزارها، میتوانید دور آبجکت موردنظرتان یک باکس بکشید. حتی در بعضی از ابزارها میتوانید آبجکت موردنظرتان را سگمنت نیز کنید. بعد از اینکه باکس را کشیدید، یک فایل شامل مشخصات آن باکس تشکیل خواهد شد. در این فایل مختصات رئوس، طول و عرض باکسی که رسم کردیم وجود دارد. این فایل معمولا پسوند xml یا csv دارد. برخی ابزار برچسبزنی عبارتند از:
در بخش بعدی نحوه برچسب زدن دادهها با LabelMe آورده شده است.
-
نحوه برچسب زدن داده ها
در این قسمت از پست « آموزش تشخیص اشیا با پایتورچ »، استفاده از LabelMe را آموزش خواهیم داد. در ویدئو زیر سه نمونه از تصاویرِ دیتاست انتخاب و با کمک LabelMe برچسب زده شدهاند.
آماده سازی پایگاه داده
در این بخش از پست « آموزش تشخیص اشیا با پایتورچ » میخواهیم دادهها را کمی جمع و جور کنیم. دادها از زمانی که خوانده میشوند تا زمانی که به شبکه داده میشوند، باید تغییر کنند. شکل ورودی در هر کدام از شبکهها و هر فریمورکی متفاوت است. بنابراین برای اینکه جواب درستی بگیریم باید دادهها را به شکل مناسب دربیاوریم. زیربخشهای بعدی به آمادهسازی دادهها اختصاص دارد …
-
خواندن فایل xml در پایتورچ
مرحله اول، استخراج اطلاعات مفید از فایلهای xml است. یک فایل xml اجزای اضافی زیاد دارد. تنها اطلاعاتی که برای ما مفید است، مختصات رئوس، طول و عرض باکس گراند تروث است. حالا ما میخواهیم اطلاعات مفید تمامی این فایلها را استخراج کرده و در یک فایل csv واحد ذخیره کنیم.
یک فایل xml از مجموعهای از المانها تشکیل شده است. هر کدام از این المانها با علامت > شروع شده و با < تمام میشوند. هر المان میتواند یک یا چند المانِ فرزند نیز داشته باشد! بدین ترتیب ساختار یک فایل xml، یک ساختار درختی است. یکی از فایلهای xml را از پوشه annotations باز کنید. ساختار درختی زیر را مشاهده خواهید کرد:
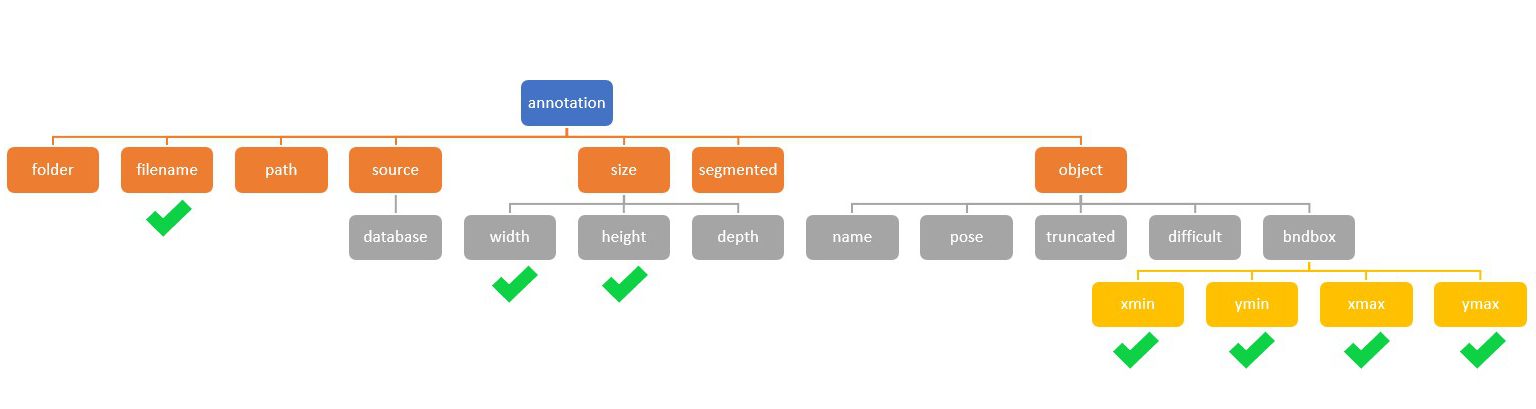
ما تنها اطلاعاتی را نیاز داریم که با تیک سبز مشخص شدهاند. گفتیم که هدف، استخراج اطلاعات موردنیاز برای هر فایل xml و ذخیره کردن آنها در یک فایل csv به صورت یکجا هست. یعنی برچسب همه 200 تصویر در یک فایل csv ذخیره شود! با کد زیر میتوانیم به هدفمان برسیم:
import os
import glob
import pandas as pd
import xml.etree.ElementTree as ET
image_path = '/content/raccoon_dataset/annotations'
xml_list = []
for xml_file in glob.glob(image_path + '/*.xml'):
tree = ET.parse(xml_file)
root = tree.getroot()
for member in root.findall('object'):
value = (root.find('filename').text,
int(root.find('size')[0].text),
int(root.find('size')[1].text),
member[0].text,
int(member[4][0].text),
int(member[4][1].text),
int(member[4][2].text),
int(member[4][3].text))
xml_list.append(value)
column_name = ['filename', 'width', 'height', 'class', 'xmin', 'ymin', 'xmax', 'ymax']
xml_df = pd.DataFrame(xml_list, columns=column_name)
xml_df.to_csv('raccoon_labels.csv', index=None)
print('Successfully converted xml to csv.')
- خط 1 تا 4: کتابخانههای لازم را ایمپورت میکنیم.
- خط 6: مسیری که برچسبها ذخیره هستند را مشخص میکنیم.
- خط 7: یک لیست خالی به نام xml_list تعریف میکنیم. تمامی اطلاعات موردنیازمان برای هر تصویر در این لیست ذخیره خواهند شد.
- خط 8: تمامی فایلهای پسوند xml که در پوشه برچسبها وجود دارد را با استفاده از دستور glob.glob(image_path + ‘/*.xml’) لیست میکنیم. سپس در لیستی که به دست آوردیم یک حلقه مینویسیم.
- خط 9 و 10: با استفاده از کتابخانه Built-in پایتون به نام ElementTree، ساختار درختی که گفتیم را استخراج میکنیم. به المانی که همه المانهای دیگر را در بر دارد، root گفته میشود. در اینجا root همان annotation است.
- خط 11: در root میگردیم و همه المانهایی که عنوانشان object است انتخاب میکنیم. در اینجا یک آبجکت بیشتر نداریم و وجود این حلقه ضروری نیست.
- خط 13 تا 20: اطلاعات موردنیاز را از root و object برمیداریم. در خط 13، 14 و 15 به ترتیب نام فایل، پهنا و ارتفاع از root استخراج میشوند. در خظ 16، کلاس آبجکت برداشته میشود. در خط 17 تا 20 نیز مختصات رئوس برچسب (کمترین و بیشترین x و y) استخراج میشوند. سپس تمامی مقادیر استخراج شده در متغیری به نام value ذخیره میشوند.
- خط 21: مقدار value را به xml_list الحاق میکنیم.
- خط 22: در این خط متغیری به نام column_name تعریف شده است. در این متغیر عنوان مقادیری که در value هستند ذخیره شده است. در واقع با این کار برای ذخیره دادهها به فرمت csv یک آمادهسازی انجام شده است.
- خط 23: با استفاده از pandas، متغیر xml_list تبدیل به یک ساختار دوبعدی میشود. نتیجه در متغیر جدیدی به نام xml_df ذخیره میشود.
- خط 24: متغیر xml_df در فایلی به نام raccoon_labels با پسوند csv ذخیره میشود.
- خط 25: این خط هم که دیگر نیازی به توضیح ندارد!
با اجرای کد بالا، نام فایل، پهنا، ارتفاع و مختصات باکسِ برچسب برای تمامی تصاویر در یک فایل csv با نام raccoon_labels ذخیره خواهد شد. مختصات باکس در واقع چهار عدد هستند. این چهار عدد در شکل زیر نشان داده شده است:

حالا باید دیتاست را برای ورود به شبکه آماده کنیم …
-
custom dataset در پایتورچ
دیتاستی که ما داریم جزو دیتاستهای تعریف شده در پایتورچ نیست. بنابراین باید یک custom dataset بسازیم. پایتورچ فرمت مشخصی برای custom dataset دارد. ابتدا باید یک کلاس بسازیم. این کلاس حداقل سه تابع init، get_item و len را باید داشته باشد. ساختار custom dataset در پایتورچ به طور کلی به شکل زیر است:
class DatasetName(torch.utils.data.Dataset):
def __init__(self, ...):
.
.
.
def __getitem__(self, ...):
.
.
.
return ...
def __len__(self):
.
.
.
return ...
- init: در این قسمت دیتاست را خوانده و تغییرات مدنظر را ایجاد میکنیم.
- get_item: این تابع را طوری مینویسیم که یک نمونه از تابع را برگرداند.
- len: این تابع نیز تعداد دادهها را برمیگرداند.
یک دیتاست پایتورچ حتما باید این سه بخش را داشته باشد. حالا ما این سه بخش را به شکل زیر مینویسیم. قبل از نوشتن دیتاست، کتابخانههای لازم را ایمپورت میکنیم:
import torch
from PIL import Image
class RaccoonDataset(torch.utils.data.Dataset):
def __init__(self, root, data_file, transforms=None):
self.root = root
self.transforms = transforms
self.imgs = sorted(os.listdir(os.path.join(root, "images")))
self.path_to_data_file = data_file
def __getitem__(self, idx):
# load images and bounding boxes
img_path = os.path.join(self.root, "images", self.imgs[idx])
img = Image.open(img_path).convert("RGB")
box_list = parse_one_annot(self.path_to_data_file, self.imgs[idx])
boxes = torch.as_tensor(box_list, dtype=torch.float32)
# there is only one class
labels = torch.ones((1,), dtype=torch.int64)
image_id = torch.tensor([idx])
area = (boxes[:, 3] - boxes[:, 1]) * (boxes[:, 2] - boxes[:, 0])
target = {}
target["boxes"] = boxes
target["labels"] = labels
target["image_id"] = image_id
target["area"] = area
if self.transforms is not None:
img = self.transforms(img)
return img, target
def __len__(self):
return len(self.imgs)
- خط 4: اسم کلاس دیتاست را RaccoonDataset انتخاب میکنیم.
- خط 5 تا 9: در این خطوط، تابع init تعریف شده است. این تابع آدرس دیتاست (root) و آدرس فایل csv که داشتیم (data_file) را دریافت میکند. همچنین یک متغیر سومی به نام transform نیز دریافت میکند. این متغیر مشخص میکند که چه پردازشهایی باید روی دادهها انجام شود.
- خط 10: تابع get_item را تعریف میکنیم. گفتیم این تابع یک نمونه از دادهها را باید بدهد. ورودی تابع get_item، اندیس نمونه موردنظر (idx) است.
- خط 12و 13: نمونه دادهای که میخواهیم خوانده شده و به RGB تبدیل میشود.
- خط 14: در دو خط قبلی تصویر را خواندیم، در این خط برچسب را میخوانیم. تابعی به نام parse_one_annot استفاده شده است. این تابع مختصات باکس گراند-تروث مربوط به تصویر موردنظرمان را برمیگرداند. اما دقت کنید که این یک تابع built-in نیست و خودمان باید آن را بنویسیم!
- خط 15: نمونه را به تنسور تبدیل میکنیم. نتیجه در متغیر boxes ذخیره میشود.
- خط 17: در این بخش نوع آبجکت را مشخص میکنیم. در این پروژه ما فقط یک آبجکت داریم. بنابراین از ones استفاده میکنیم.
- خط 18: در این خط اندیس نمونه داده به تنسور تبدیل شده و در متغیر image_id ذخیره میشود.
- خط 19: مساحت باکس گراند تروث، محاسبه شده و در متغیر area ذخیره میشود.
- خط 20 تا 24: در این خطوط یک دیکشنری به نام target میسازیم و تمامی ویژگیهایی که برای باکس گراند-تروث استخراج کردیم را در آن ذخیره میکنیم.
- خط 25 و 26: در صورتی که transform داشته باشیم این بخش اجرا میشود. در این پروژه به منظور سادهسازی هیچ transform-ی اعمال نشده است. فقط دادهها به تنسور تبدیل شدهاند.
- خط 27: تصاویر و برچسبها برگردانده میشوند.
- خط 28: تابع len در این خط تعریف میشود. این تابع باید حجم دیتاست را برگرداند.
- خط 26: با استفاده از تابع len پایتون، تعداد نمونههای دیتاست را گرفته و return میکنیم.
خب حالا برویم تابع را تعریف کنیم:
def parse_one_annot(path_to_data_file, filename): data = pd.read_csv(path_to_data_file) boxes_array = data[data["filename"] == filename][["xmin", "ymin", "xmax", "ymax"]].values return boxes_array
- خط 1: تابع parse_one_annot تعریف شده که آدرس دادهها و نام یک داده را میگیرد.
- خط 2: فایل csv که در ابتدای این پست ساختیم را فراخوانی میکنیم.
- خط 3: نام فایل را که داریم. در فایل csv، داده موردنظرمان را با استفاده از نام داده پیدا میکنیم. سپس اطلاعات آن داده را برمیداریم.
- خط 5: اطلاعاتی که استخراج کردیم را برمیگردانیم.
تا اینجا ما تمپلیتی که برای دیتاست پایتورچ گفتیم را کامل کردیم. بد نیست کلاسی که نوشتیم را تست کنیم نه؟ برای تست کلاسی که نوشتیم کافی است بنویسیم:
dataset = RaccoonDataset(root= "/content/raccoon_dataset",
data_file= "/content/raccoon_labels.csv")
dataset.__getitem__(0)
با اجرای کد بالا خواهیم داشت:
(<PIL.Image.Image image mode=RGB size=650x417 at 0x7F3D1400E9B0>,
{'area': tensor([141120.]),
'boxes': tensor([[ 81., 88., 522., 408.]]),
'image_id': tensor([0]),
'labels': tensor([1])})
مشاهده میکنید که با get_item توانستیم یک نمونه از دادهها را گرفته و نمایش دهیم! حالا که کاستوم دیتاست در پایتورچ را نوشتیم، باید دیتالودر بسازیم. بخش بعدی از پس « آموزش تشخیص اشیا در پایتورچ » به ساختن دیتالودر در پایتورچ اختصاص دارد …
-
جدا کردن دادههای تست
قبل از نوشتن دیتالودر، باید ابتدا تعدادی از دادهها را برای تست جدا کنیم. برای این کار ابتدا لیستی از اعداد تصادفی به تعداد دادهها میسازیم. سپس این لیست را به هم ریخته و از آن برای جدا کردن تعدادی از دادهها برای تست استفاده میکنیم:
torch.manual_seed(1) indices = torch.randperm(len(dataset)).tolist() dataset = torch.utils.data.Subset(dataset, indices[:-40]) dataset_test = torch.utils.data.Subset(dataset_test, indices[-40:])
- خط 1: همانطور که در پستهای قبلی هم گفتیم، از seed برای کنترل کردن shuffle استفاده میشود!
- خط 2: با استفاده از torch.randperm، لیستی از اعداد تصادفی میسازیم. این اعداد از صفر شروع میشوند و به تعداد دادهها هستند. مثلا اگر 20 تا داده داریم، اعدادی که با randperm تولید میشوند باید بین 0 تا 19 باشد.
- خط 3 و 4: با استفاده از دستور torch.utils.data.Subset تعداد 160 داده را برای آموزش برمیداریم. 40 داده باقیمانده را برای تست برمیداریم. دقت کنید که ما اندیسها را بهم ریختیم. بنابراین انتخاب دادهها برای آموزش و ارزیابی به صورت تصادفی انجام شده است.
خب حالا میتوانیم برویم سراغ ساختن دیتالودر …
-
نوشتن Dataloader در پایتورچ
در این بخش از « آموزش تشخیص اشیا با پایتورچ » میخواهیم دیتالودر بسازیم. واضح است که برای ساختن dataloader در پایتورچ، از دستور torch.utils.data.DataLoader استفاده میکنیم:
data_loader = torch.utils.data.DataLoader( dataset, batch_size=2, shuffle=True,
num_workers=4, collate_fn=collate_fn)
data_loader_test = torch.utils.data.DataLoader(dataset_test, batch_size=1,
shuffle=False, num_workers=4,
collate_fn=collate_fn)
print("We have: {} examples, {} are training and {} testing".format(len(indices), len(dataset), len(dataset_test)))
- خط 1: اندازه بچ را برای آموزش، 2 در نظر میگیریم. shuffle را True میکنیم. num_workers را برابر با 4 در نظر میگیریم. collate_fn را نیز برابر با collate_fn گذاشتیم! این collate_fn دومی که گفتیم تابعی است که باید خودمان تعریفش کنیم.
- خط 3: کلیات این دستور همانند دستور قبلی است. با این تفاوت که اندازه بچ را برای تست، 1 در نظر گرفتهایم. shuffle را False کردیم. لزومی ندارد برای دادههای تست بچ بزرگتر از یک باشد. یا اینکه چه لزومی دارد که ترتیب دادهها را در تست به هم بزنیم؟
- خط 6: در این خط صرفا تعداد دادههای تست و آموزش را نمایش میدهیم.
اما تابع collate_fn چطور تعریف میشود؟ این تابع درواقع بچ کردن دادهها را انجام میدهد. در این تابع ما باید تصاویر و برچسبها را جدا کنیم. طوری که همه تصاویر با هم و همه برچسبها با هم برگردانده شود:
def collate_fn(batch):
return tuple(zip(*batch))
برای این کار از zip استفاده میکنیم و سپس همه را در tuple گذاشته و برمیگردانیم. شاید این قسمت برایتان زیاد ملموس نباشد. برای درک بهتر بیایید یکی از بچها را از دیتالودر ببینیم:
next(iter(data_loader))
نتیجه اجرای کد بالا به شکل زیر خواهد بود:
((<PIL.Image.Image image mode=RGB size=261x193 at 0x7F1732EE6668>,
<PIL.Image.Image image mode=RGB size=604x481 at 0x7F1732EEF400>),
({'area': tensor([22152.]),
'boxes': tensor([[107., 10., 249., 166.]]),
'image_id': tensor([113]), 'labels': tensor([1])},
{'area': tensor([124533.]), 'boxes': tensor([[ 99., 53., 402., 464.]]),
'image_id': tensor([10]), 'labels': tensor([1])}))
مشاهده میکنید که تصاویر با هم در یک tuple ، برچسبها با هم در tuple دیگر و هردو در یک tuple دیگر ذخیره شدهاند. دقت کنید، تصاویر چون ابعاد متفاوتی دارند به صورت آبجکت PIL ذخیره شدهاند. در غیر اینصورت باید تمامی تصاویر را هماندازه میکردیم. خود شبکه اینطور تصاویر را میخواهد. پس ما هم تغییری در تصاویر نخواهیم داد! کار ما با دادهها تمام شد. در بخش بعدی از « آموزش تشخیص اشیا با پایتورچ » باید برویم سراغ مدل …
تعریف مدل Faster RCNN در پایتورچ
در این پروژه ما میخواهیم از یادگیری انتقالی استفاده کنیم. در پایتورچ 2 مدل pretrained برای object detection و object segmentation وجود دارد. این مدلهاعبارتند از Faster R-CNN ResNet-50 FPN و Mask R-CNN ResNet-50 FPN. هردوی این مدلها روی دیتاست coco آموزش دیدهاند. طبیعتا ما باید از مدل Faster RCNN استفاده کنیم. در بخش بعدی به صورت خلاصه ساختار این شبکه را بررسی خواهیم کرد …
شبکه Faster RCNN
شبکه Faster RCNN کمی پیچیده است. اما ساختار کلی این شبکه به شکل زیر است:

همه چیز از یک تصویر شروع میشود. انتظار داریم که شبکه موارد زیر را به ما بدهد:
- لیستی از باندینگباکسها
- یک برچسب برای هر باندینگ باکس
- یک احتمال برای هر باندینگ باکس
ابتدا تصاویر ورودی به یک شبکه CNN داده میشوند. شبکه CNN از این تصاویر یکسری نگاشتِ ویژگی استخراج میکند. ویژگیهای استخراج شده، به یک شبکه RPN یا Region Proposal Network داده میشود. این شبکه وظیفه دارد که به تعداد مشخصی باندینگ باکس یا Region Proposal پیدا کند.
یکی از چالشهای آبجکت دیتکشن با یادگیری عمیق همین تولید Region Proposal-هایی با ابعاد مختلف است. شبکههای عمیق معمولا یک خروجی با طول ثابت دارند. مثلا یک شبکه کلاسبند، خروجیاش یک تنسور به طول N است که N تعداد کلاسهاست. مشکلی که گفتیم در RPN با کمک آنکورها حل شده است.
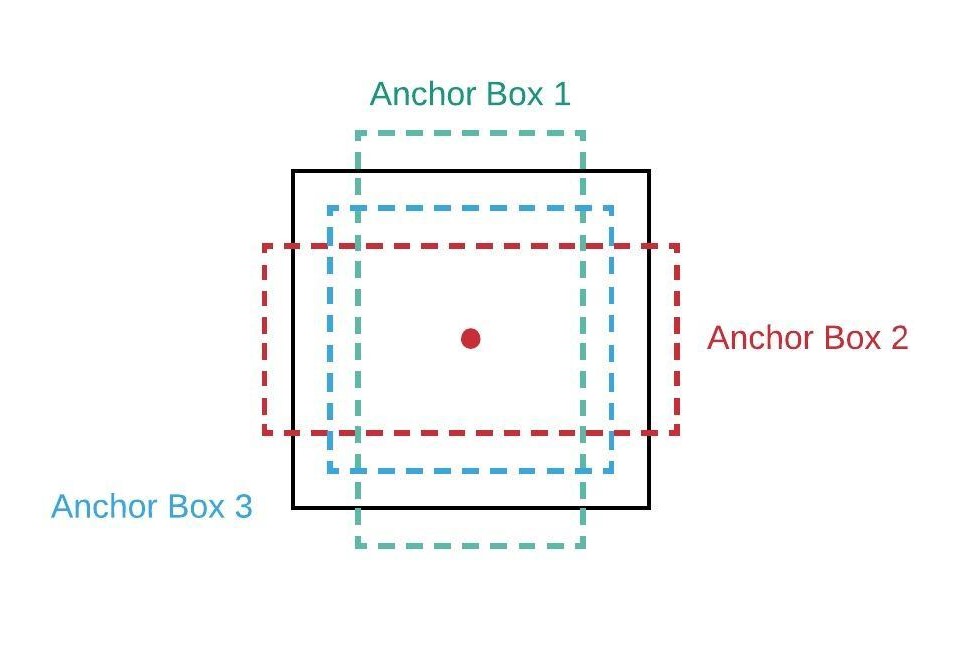
آنکورها، مجموعه باکسهایی با طول ثابت هستند. آنها به صورت یونیفورم روی کل تصویر قرار داده میشود. حالا به جای تخمین مکان آبجکت، مسئله به دو بخش زیر تبدیل میشود. برای هر آنکور:
- آیا این آنکور آبجکت مورد نظرمان را دارد؟
- اگر جواب سوال قبل بله هست، آنکور چقدر باید تغییر کند که بر آبجکت فیت شود؟
تا اینجا استخراج ویژگی انجام شد و باندینگ باکسهایی که ممکن است آبجکت موردنظرمان را شامل شود، به دست آمدند. حالا از ROI Pooling باید استفاده کنیم تا فقط ویژگیهای مربوط به آبجکت استخراج شود. نهایتا این ویژگیها به یک شبکه RCNN یا fast RCNN داده میشوند تا:
- کلاس آبجکت مشخص شود.
- باندینگ باکس، تنظیم شده تا بهتر بر آبجکت فیت شود.
ما به صورت بسیار بسیار خلاصه شبکه Faster RCNN را بررسی کردیم. طبیعی است که نکات زیادی را نگفتیم. اما به طور کلی، ساختار و عملکرد شبکه Faster RCNN را توضیح دادیم.
شبکه Faster RCNN در پایتورچ
این بخش از « آموزش تشخیص اشیا با پایتورچ » به تعریف مدل در پایتورچ اختصاص دارد. ما میخواهیم یک تابع تعریف کنیم که تعداد کلاسها را دریافت کرده و با توجه به آن مدل را تعریف کند. مدلی که انتخاب کردیم، شبکه Faster RCNN است. همچنین تصمیم داریم از یادگیری انتقالی استفاده کنیم. زیرا دادههای ما برای آموزش کل شبکه از scratch کم است. از این رو دست به دامان پایتورچ میشویم.
گفتیم در پایتورچ و کتابخانه torchvision، دو شبکه pretrained برای آبجکت دیتکشن وجود دارد: Faster R-CNN ResNet-50 FPN و Mask R-CNN ResNet-50 FPN. که ما از Faster RCNN استفاده میکنیم. این شبکهها بر روی دیتاست معروف COCO آموزش دیدهاند. برای تعریف مدل تابعی به نام get_model مینویسیم. لایه آخر مدل را باید طوری تغییر دهیم که مناسب با تعداد کلاسهای خودمان شود.
from torchvision.models.detection.faster_rcnn import FastRCNNPredictor
def get_model(num_classes):
# load an object detection model pre-trained on COCO
model = torchvision.models.detection.fasterrcnn_resnet50_fpn(pretrained=True)
# get the number of input features for the classifier
in_features = model.roi_heads.box_predictor.cls_score.in_features
# replace the pre-trained head with a new on
model.roi_heads.box_predictor = FastRCNNPredictor(in_features, num_classes)
return model
- خط 1: در این خط کتابخانههای مورد نیاز را ایمپورت میکنیم.
- خط 3: تابع get_model، تعداد کلاسها را دریافت میکند.
- خط 5: در این خط مدل آموزش دیده با وزنهایش دانلود میشود. دقت کنید که برای Transfer Learning، مقدار pretrained را باید حتما True کنید.
- خط 7: خب ما با بخش استخراج ویژگی یعنی ResNet و شبکه FPN مشکلی نداریم. اما در بخش آخر، یعنی جایی که نتایج حاصل از دو شبکه کلاسبندی میشوند نیاز به تغییر داریم. مسئلهای که ما میخواهیم حل کنیم تنها یک آبجکت دارد. یعنی 2 کلاس داریم. بنابراین باید کلاسیفایر را کمی تغییر دهیم! همچنین کلاسیفایر حتی اگر دو کلاس داشت هم باید از صفر آموزش میدید. چون مسئله ما کاملا متفاوت است. برای رفع این مشکل ابتدا تعداد ویژگیهایی که از FPN وارد ROI-head میشود را پیدا میکنیم. این کار با دستوراتی که در این خط نوشتیم انجام شده است.
- خط 9: از تعداد ویژگیهایی که در بخش قبل به دست آمد استفاده کرده و یک کلاسیفایر جدید Fast RCNN تعریف میکنیم. این کلاسیفایر در خط 1 ایمپورت شده بود!
- خط 10: در نهایت هم مدل برگرذانده میشود.
تا اینجا تابعی نوشتیم که مدل را برایمان تعریف کند. حالا نوبت به استفاده از این تابع میرسد. همچنین مدل باید کانفیگ شود:
device = torch.device('cuda') if torch.cuda.is_available() else torch.device('cpu')
# our dataset has two classes only - raccoon and not racoon
num_classes = 2
# get the model using our helper function
model = get_model(num_classes)
# move model to the right device
model.to(device)
# construct an optimizer
params = [p for p in model.parameters() if p.requires_grad]
optimizer = torch.optim.SGD(params, lr=0.005,
momentum=0.9, weight_decay=0.0005)
# and a learning rate scheduler which decreases the learning rate by # 10x every 3 epochs
lr_scheduler = torch.optim.lr_scheduler.StepLR(optimizer,
step_size=3,
gamma=0.1)
- خط 1: این خط باید برایتان آشنا باشد!
- خط 3 ، 5 و 7: در این دو خط تعداد کلاسها مشخص شده است. سپس از آن برای تعریف مدل با استفاده از تابع get_model استفاده شده است. سپس در صورت وجود، مدل به جی پی یو داده شده است.
- خط 9 و 10: در این بخش پارامترهایی که باید آموزش ببینند در متغیر params ذخیره شدند. سپس این پارامترها به بهینهساز داده شدهاند. مشاهده میکنید که از بهینه ساز SGD با نرخ یادگیری 0.005 ، مومنتوم برابر با 0.9 و weight_decay برابر با 0.0005 استفاده شده است.
- خط 13: در این خط lr_scheduler تعریف شده است. step_size برابر با 3 و گاما برابر با 0.1 در نظر گرفته شده است.
حالا نوبت آموزش مدل است. برویم بخش بعدی …
آموزش مدل
خب تا اینجا دادهها را برای ورود به شبکه پردازش کردیم. همچنین مدل را تعریف و کانفیگ کردیم. حالا نوبت به آموزش مدل است. تعداد epoch-ها را 10 در نظر میگیریم. سپس حلقه آموزش را اینطور مینویسیم:
# let's train it for 10 epochs
num_epochs = 10
for epoch in range(num_epochs):
# train for one epoch, printing every 10 iterations
loss = train_one_epoch(model, optimizer, data_loader, device)
# update the learning rate
print('epoch [{}]: \t lr: {} \t loss: {} '.format(epoch, lr_scheduler.get_lr(),loss))
lr_scheduler.step()
- خط 2: تعداد ایپوک ها در این خط تعیین شدهاند.
- خط 3: حلقهای نوشتیم که به تعداد ایپوک ها تکرار میشود.
- خط 4: در این خط آموزش مدل اتفاق میافتد! برای این کار ما یک تابع به نام train_one_epoch نوشتیم. این تابع مدل، بهینه ساز، دیتالودر و device را میگیرد و مقدار اتلاف را برمیگرداند. ساختار این تابع را بعدا توضیح میدهیم!
- خط 6: در این خط مقدار اتلاف، نرخ یادگیری و شماره ایپوک را نمایش میدهیم.
- خط 7: در این خط به lr_scheduler میگوییم که یک قدم تغییر کند! قدمها را هم که قبلا تعیین کردیم که چقدر باید باشد …
اما تابع train_one_epoch چیست. دقت کنید این تابع باید قبل از حلقه آموزش نوشته شود. این تابع را به صورت زیر مینویسیم:
import math
def train_one_epoch(model, optimizer, data_loader, device):
model.train()
total_loss = 0
for images, targets in data_loader:
images = list(image.to(device) for image in images)
targets = [{k: v.to(device) for k, v in t.items()} for t in targets]
loss_dict = model(images, targets)
losses = sum(loss for loss in loss_dict.values())
total_loss += losses
optimizer.zero_grad()
losses.backward()
optimizer.step()
return total_loss/data_loader.__len__()
- خط 1: کتابخانه math را فراخوانی کردیم.
- خط 2: نیازی به توضیح نمیبینم!
- خط 3: تعیین میکنیم که در مُد آموزش هستیم.
- خط 4: متغیری به نام total_loss تعریف میکنیم. مقدار این متغیر صفر است و بعدا از آن برای محاسبه اتلاف یک بچ استفاده خواهیم کرد.
- خط 5: حلقهای مینویسیم که یکی یکی دادهها (تصاویر و برچسبها) را از دیتالورد بگیرد.
- خط 6: تعیین میکنیم که محاسبات مربوط به تصاویر در GPU (در صورت وجود) انجام شود.
- خط 7: در این بخش برچسبها هم به GPU فرستاده میشوند! اما دقت کنید که تک تک آیتمهای دیکشنری را جدا کرده و فقط مقدار value-ها را به GPU انتقال دهیم.
- خط 9: دادهها و برچسبها را به مدل میدهیم و مدل اتلاف را محاسبه میکند. دقت کنید که اتلاف یک عدد نیست! بلکه یک دیکشنری است که چندین اتلاف را در خود دارد. مثلا ماژول RPN برای خودش اتلاف جداگانه در پروسه آموزش دارد. یا تخمین کلاس آبجکت یک اتلاف جداگانه دارد.
- خط 10: دیکشنری اتلافی که در خط قبلی به دست آوردیم. در این خط، همه این اتلافها را با هم جمع میکنیم.
- خط 11: مقدار اتلاف را در متغیر total_loss میریزیم.
- خط 13 و 14: ابتدا گرادیانها را صفر شده و سپس گرادیانهای جدید محاسبه میشوند.
- خط 15: الگوریتم بهینهسازی پارامترها را با توجه به گرادیانهای محاسبه شده آپدیت میشوند.
- خط 16: بعد از اینکه شبکه با همه دادهها آموزش دید، میانگین اتلاف برگردانده میشود.
اینم از این! بعد از آموزش، نوبت به ارزیابی میرسد. برویم بخش بعدی …
خروجی مدل آبجکت دیتکشن Faster RCNN
در این بخش میخواهیم نتیجه شبکه برای دادههای تست را بررسی کنیم. ما به دنبال به دست آوردن متریک نیستیم. بلکه میخواهیم ببینیم خروجی مدل برای دادههای تست چگونه است. برای این کار تابعی به نام evaluate نوشتیم:
import cv2
import matplotlib.pyplot as plt
import matplotlib.patches as patches
def evaluate(model, data_loader_test, device=device):
model.eval()
with torch.no_grad():
cnt = 0
for images , targets in data_loader_test:
images = list(image.to(device) for image in images)
targets = [{k: v.to(device) for k, v in t.items()} for t in targets]
out = model(images)
scores = out[0]['scores'].cpu().numpy()
inds = scores > 0.7
bxs = out[0]['boxes'].cpu().numpy()
bxs = bxs[inds]
gt = targets[0]['boxes'].cpu().numpy()
gt = gt[0]
img = images[0].permute(1, 2, 0).cpu().numpy()
for box in bxs:
fig,ax = plt.subplots(1)
# Display the image
ax.imshow(img)
# Create a Rectangle patch
rect1 = patches.Rectangle((int(box[0]),int(box[1])),abs(box[0]-box[2]),
abs(box[1]-box[3]),linewidth=3,edgecolor='r',facecolor='none')
ax.add_patch(rect1)
rect2 = patches.Rectangle((int(gt[0]),int(gt[1])),abs(gt[0]-gt[2]),
abs(gt[1]-gt[3]),linewidth=3,edgecolor='g',facecolor='none')
ax.add_patch(rect2)
# Add the patch to the Axes
fig.savefig("/content/output_images/{}.png".format(cnt), dpi=90, bbox_inches='tight')
cnt = cnt + 1
- خط 1 تا 3: کتابخانههای موردنیاز را دانلود میکنیم.
- خط 5: تابع evaluate را با ورودیهای موردنیاز تعریف میکنیم.
- خط 8 و 7: مُد را در حالت ارزیابی گذاشته و محاسبه گرادیان را غیرفعال میکنیم.
- خط 9: یک شمارنده تعریف میکنیم. بعدا کاربردش را میبینید.
- خط 10: دادهها را یکی یکی میگیریم.
- خط 12 و 13: مشابه تابع آموزش، دادهها را برای افزایش سرعت به GPU میبریم.
- خط 15: داده را به مدل داده و نتیجه را در out ذخیره میکنیم.
- خط 16 و 17: شبکه برای هر باکس یک امتیاز یا score میدهد. ما از این امتیازها استفاده کرده و فقط آنهایی را برمیداریم که بیشتر از 0.7 هستند. البته در این خط فقط اندیسها را برداشتیم.
- خط 18 و 19: از اندیسهایی که در بخش قبل به دست آوردیم استفاده کرده و باکسهایی که امتیازشان بالای 0.7 هست را برمیداریم. این باکسها در متغیر bxs ذخیره میکنیم.
- خط 20 و 21: باندینگ باکس Ground truth را استخراج میکنیم.
- خط 22: تصویر را هم ابعادش را طوری تغییر میدهیم که برای نمایش مناسب باشد.
- خط 24: در متغیر bxs یک حلقه مینویسیم. یادآوری میکنم، این متغیر باندینگ باکسهایی را در خود دارد که امتیاز خوبی دارند.
- خط 26 تا 35: در این خطوط ما باکسی که شبکه پیشبینی کرده و باکس گراند-تروث را بر روی تصویر رسم میکنیم. پیشبینی شبکه قرمز و گراند تروث به رنگ سبز است.
- خط 37: تصاویر حاصل در پوشه output_images ذخیره خواهد شد. نام تصاویر را همان شمارنده cnt گذاشتیم.
- خط 38: یکی به شمارنده اضافه میکنیم تا تصاویر replace نشوند!
خب احتمالا همین الان هم یکسری تصاویر میبینید! به پوشه output_images بروید و پیشبینیهای شبکه را مشاهده کنید. میبینید که شبکه نسبتا خوب کار میکند. در بعضی از موارد خیلی خوب کار کرده. اما اصلا دقیق نیست. طبیعتا اگر بخواهیم پیشبینیهای دقیقتری داشته باشیم باید بیشتر مایه بگذاریم! آموزش و دادههای بیشتر قطعا به دقت شبکه خواهند افزود.
به هر حال، بیایید کمی نتایج را ببینیم:

خب ما توانستیم یک شبکه آبجکت دیتکشن با Faster RCNN در پایتورچ انجام دهیم. ادامه پروژه و رسیدن به دقتهای بهتر را به دستان پر توان شما میسپاریم.
برای دسترسی به پست-پروژههای دیگر کلیک کنید:
در پست « آموزش تشخیص اشیا با پایتورچ »، صفر تا صد یک پروژه تشخیص اشیا را در پایتورچ آموزش دادیم. امیدوارم که این آموزش برای شما مفید باشد. پیشنهادات و نظرات خودتان را برایمان کامنت کنید.
مطالب زیر را حتما مطالعه کنید

تشخیص کرونا با یادگیری عمیق

هوش مصنوعی در بورس

رگرسیون با mlp و تنسورفلو

دسته بندی با mlp و تنسورفلو
12 دیدگاه
به گفتگوی ما بپیوندید و دیدگاه خود را با ما در میان بگذارید.
سلام ممنون از آموزشتون
من هم مثل سایر دوستان خطای AttributeError: ‘Image’ object has no attribute ‘to’ رو دارم. چطور داده ها رو به تنسور تبدیل کنم؟
سلام
من ویدیوهای آموزشی مربوط به تشخص اشیاء با استفاده از پایتورچ رو خریداری کردم و دیدم. بسیار مفید و ساده و قابل فهم بیان شده بود. از این بابت بسیار سپاسگزارم
اما من به مشکلی برخوردم که توی اون آموزش چیزی در موردش بیان نشده است. اگه راهنمایی بفرمایید که بتوانم این مشکل را حل کنم ممنون میشم.
من نیاز دارم که از لایه ‘fc6’ برای هر باکس شناسایی شده شی، یک بردار ویژگی 1024 بعدی دریافت کنم. برای این کار از تابع register_forward_hook بر روی لایه مذکور استفاده کردم و توانستم خروجی اکتیویشن این لایه را دریافت کنم. حالا مشکل اینجاست که خروجی اکتیویشن لایه fc6 برای تمام region proposalهاست نه باکسهای شناسایی شده نهایی. مثلا در یک تصویر که نهایتا 48 باکس شی شناسایی شده است من 1000 بردار خروجی با ابعاد 1024 از لایه fc6 دریافت میکنم. در واقع برای هر تصویر با هر تعداد باکس شی شناسایی شده، خروجی اکتیویشن لایه fc6 دارای ابعاد 1024*1000 است. الان سوالم اینجاست که من چطوری میتونم از بین این 1000 بردار خروجی، بردارهای متناظر با باکسهای شناسایی شده نهایی را پیدا کنم؟
به نظر خودم باید خروجی اکتیویشن لایه ‘cls_score’ میتواند کمک کننده باشد اما هر چه تلاش کردم به نتیجه نرسیدم.
اگه لطف کنید و راهنمایی کنید ممنون میشم
ببخشید اگه متن طولانی شد.
سلام
مثل همیشه عااااااالی
تو این پست ابزار لیبل زدن برای تصاویر معرفی شدن.
برای من سوال شد که آیا راهی برای لیبل زدن داده های متنی وجود داره؟؟؟؟
ممنون ازشما
سلام
سپاس 🌹🙏
امروزه ابزار لیبل بسیار زیاد شده و حتی شرکتهای بزرگ هم این ابزارها رو ارائه میدن. حتی نسخههای پولی هم وجود داره. ابزار لیبلزدن تصویر، متن، صوت و غیره وجود داره. مثلا در این لینک مجموعهای از ابزارهای لیبلزدن معرفی شده.
سپااااس
درود
بسیار سپاسگزارم بابت آموزشهای فوقالعادهتون
من هنگام اجرا خطای زیر رو دارم. میشه راهنمایی بفرمایید مشکل از کجاست؟
images = list(image.to(device) for image in images)
AttributeError: ‘Image’ object has no attribute ‘to’
سلام
سپاس 🌹🙏
اتریبیوت to برای یک تنسور تعریف شده، یعنی image باید تنسور باشه. درحالیکه، الان image از جنس Image هست. Image اشاره به فریمورک pil میکنه. یعنی این تصاویر هنوز از pil به تنسور تبدیل نشدن.
salam
in code niaz be vervion nasbiye khassi dare? tooye train_one_epock, khata daram
to in khat
images = list(image.to(device) for image in images)
in khata ro daram
AttributeError: ‘Image’ object has no attribute ‘to’
pishnahadi hast baraye bartaraf kardanesh
?
سلام ، همچین مقاله فوق العاده ای برای یولو ندارید ؟
سلام
سپاس 🌹
یک مقاله از یولو در وبلاگ هست که فقط تئوری تشریح شده (لینک). متاسفانه فعلا پست وبلاگی از کدنویسی یولو نداریم.
اون مقاله رو دیدم اونم بین تمام مقالاتی که تا حالا خوندم بی نظیر بود ، اگر میشه راهی برای ارتباط با حضرتعالی بفرمایید تا بتونم در مورد FINE TUNE کردن و یا آموزش یولو ازتون کمک بگیرم .
بله حتما،
با مهندس اشرفی یه زمانی رو هماهنگ میکنیم و زمانش رو براتون ایمیل میکنیم.