
تشخیص کرونا با یادگیری عمیق
این روزها از هر ده جملهای که میگوییم، حداقل در یکی از آنها کلمه کرونا وجود دارد! یکی از راههای تشخیص کرونا، استفاده از سی تی اسکن ریه است. موضوع این پست، تشخیص کرونا با یادگیری عمیق است. در این پست میخواهیم با استفاده از تصاویر سی تی اسکن ریه و شبکه VGG، کرونا را تشخیص دهیم. با هوسم همراه باشید…
توجه این پروژه با اهداف آموزشی تهیه شده است و ارزش تشخیصی ندارد.
بیماری کرونا چیست
کروناویروسها خانواده بزرگی از ویروسها هستند که در سال 1960 کشف شدند. به طور طبیعی ویروسهای کرونا در پرندگان و پستانداران وجود دارند. اما تاکنون هفت نوع کروناویروس کشف شدهاند که انسان به انسان میتوانند منتقل شوند (منبع). یکی از این کروناویروسها که اخیرا زندگی جهانیان را تحت تاثیر قرار داده است، سندروم حاد تنفسی یا همان کووید-19 است. شیوع این ویروس در دسامبر 2019 از شهر ووهان چین شروع و در عرض چندماه تبدیل به یک همهگیری جهانی شد.
پیرامون نحوه انتقال این بیماری به انسان و منشا آن هنوز هیچ اطلاعات موثقی در دسترس نیست. در ابتدای همهگیری، این بیماری به خفاشها نسبت داده شد. سپس گفته شد که احتمالا مورچهخوار پولکدار عامل این بیماری است. تنها چیزی که با اطمینان از آن صحبت میشود این است که ماجرا از بازار عمدهفروشی غذاهای دریایی هوانان، شروع شده است! البته برخی ادعا داشتند که این بیماری ساخته دست بشر است و در آزمایشگاه تولید شده است. ولی تاکنون منشا اصلی آن توسط هیچ منبع موثقی تایید نشده است.
علائم و روش تشخیص کرونا
رایجترین نشانههای ابتلا به کووید-19 تب، خستگی و سرفه خشک است. ممکن است فرد مبتلا علائم دیگری از قبیل کوفتگی، آبریزش بینی، گلودرد یا اسهال نیز داشته باشد (منبع). اما یک پزشک چطور کرونا را تشخیص میدهد. مثلا چک کردن دمای بدن سادهترین راه تشخیص این بیماری است که اصلا هم دقیق نیست. یکی دیگر از راههای تشخیص بیماری، اسکن قفسه سینه است. یعنی از قفسه سینه عکسبرداری شده و سلامت ریهها به دقت بررسی میشوند. از این رو ما در این پست پروژهای انتخاب کردیم که برای تشخیص کرونا با یادگیری عمیق از تصاویر CT سینه استفاده میکند.
پایگاه داده کووید 19
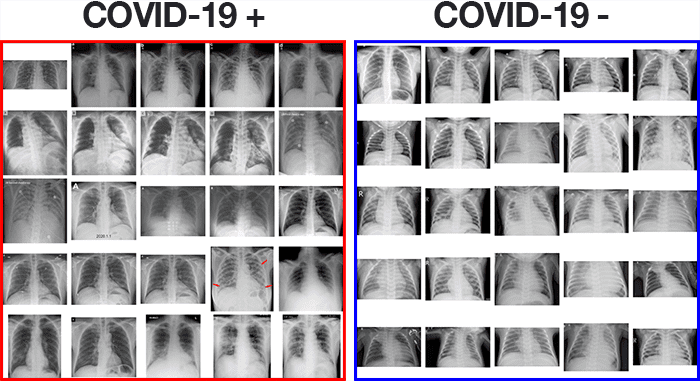
طبیعتا برای تشخیص کرونا با یادگیری عمیق نیاز به داده داریم. مجموعه دادههای سیتیاسکن کرونا-مثبت که ما برای این آموزش استفاده خواهیم کرد توسط جوزف کوهن، فوقدکتری دانشگاه مونترال گردآوری شدهاست. برای دادههای کرونا-منفی یا نمونههای نرمال از دیتاست Chest X-Ray Images از سایت Kaggle استفاده میکنیم. در نهایت یک پایگاهداده خواهیم داشت که میتوانیم یک شبکه عمیق را با آن آموزش دهیم. اما چگونه این پایگاه داده را بسازیم؟ در بخش بعدی نحوه ساخت پایگاه داده آورده شده است …
نحوه ساختن پایگاه داده کووید 19
در این بخش از پست تشخیص کرونا با یادگیری عمیق ، میخواهیم یک پایگاه داده کووید-19 بسازیم. در خیلی از آموزشها، نحوه مرتب کردن دادهها و ساختن دیتاست گفته نمیشود. و فقط دادهها برای دانلود قرار داده میشود. اما ما میخواهیم این فرآیند را برای شما باز کرده و توضیح دهیم. انتخاب دادههای CT قفسه سینه نکته ظریف و مهمی دارد که دانستن آن خالی از لطف نیست!
انتخاب دادههای Covid-19
آقای JOSEPH PAUL COHEN، مجموعهای از دادههای CT قفسه سینه که شامل کووید-19 هم هست جمعآوری کردند. علاوه بر دادههای کووید، دادههای مربوط به بیماریهای ریوی دیگر از جمله سارس، ARDS و … نیز وجود دارند. پس در وهله اول ما باید دادههای کووید را از این دادهها جدا کنیم. دادهها در پیج گیتهاب آقای COHEN وجود دارند (اینجا). تصاویر CT همگی با هم در پوشهای به نام Images وجود دارند. یک فایل راهنما به نام metadata.csv نیز وجود دارد. این فایل را دانلود و باز کنید:
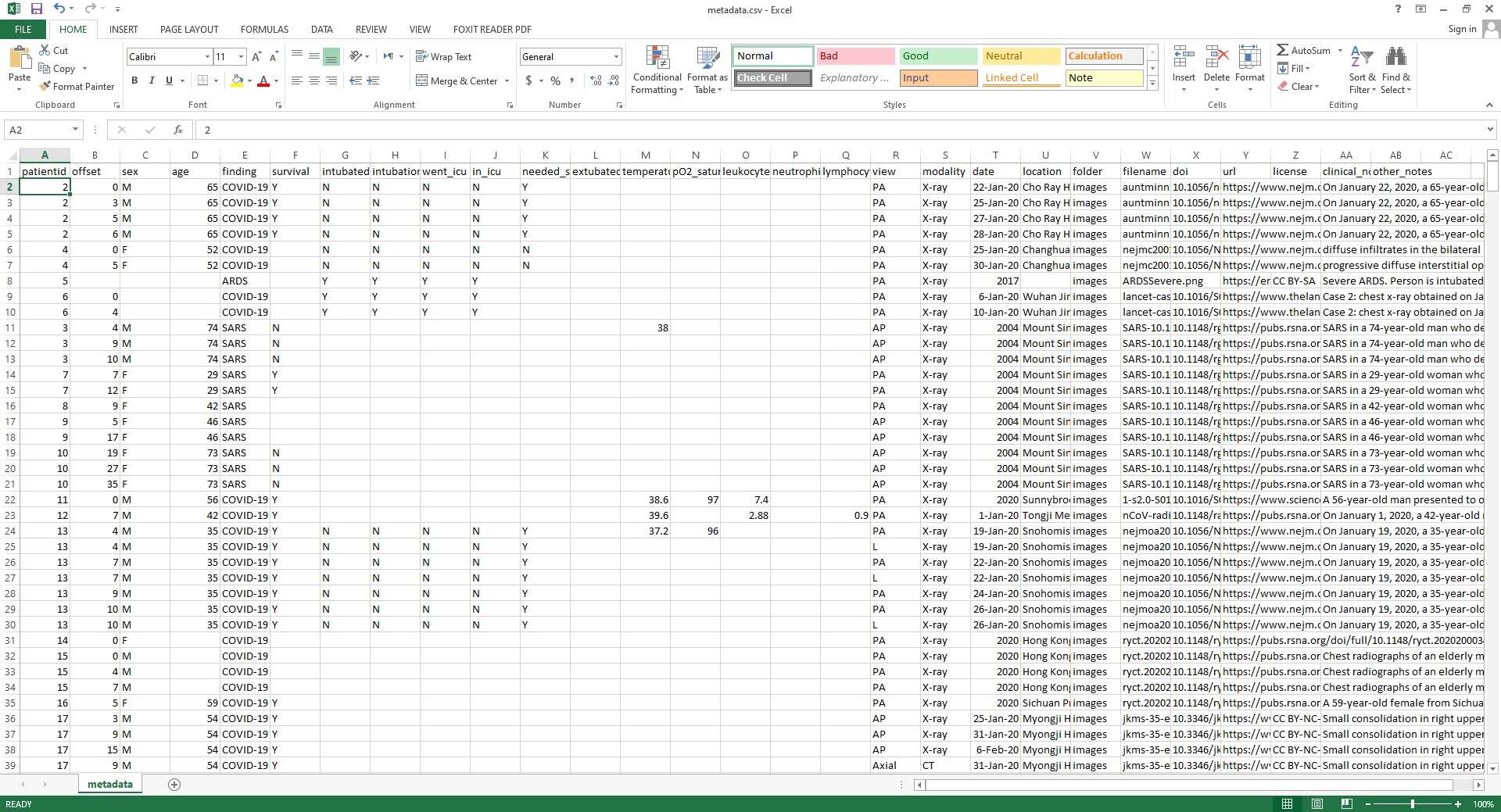
چند ستون مهم را با هم مرور میکنیم. در ستون اول، Id هر بیمار وجود دارد. در ستون findings مشاهده میکنید که تشخیص پزشک آورده شده است. در ستون view، نمای تصویربرداری آورده شده است. در بخش filename نیز نام فایل آورده شده است. یک نکته مهم در این قسمت وجود دارد. یک بار دیگر ستون patientid را نگاه کنید. مشاهده میکنید که در بعضی موارد چندین Id یکسان وجود دارد. نکته دقیقا همینجاست. برای هر بیمار ممکن است چندین بار تصویربرداری با آفستهای متفاوت انجام شده باشد.
چرا این مسئله خوب نیست؟ فکر کنید از یک بیمار 5 تصویر وجود داشته باشد. موقع تقسیم دادهها به تست و آموزش، که معمولا هم به صورت تصادفی انجام میشود، 3 تا از تصاویر در تست بیفتد و 2 تا در داده آموزش. چه اتفاقی میافتد؟ نتیجه این است که شبکه چون داده را در آموزش دیده است، در تست به راحتی میتواند آن را دستهبندی کند. درواقع شبکه تقلب کرده است.
برای حل این مشکل، اگر ما از هر بیمار فقط یک تصویر برداریم، تعدادی از دادهها را از دست خواهیم داد. بنابراین باید تلاش کنیم دادهها را بر اساس شماره Id ذخیره کنیم. برای این کار ابتدا باید فایل metadata.csv را بخوانیم:
import pandas as pd csvPath = '/content/covid-chestxray-dataset/metadata.csv' df = pd.read_csv(csvPath)
سپس باید هر ردیف را بررسی کنیم. تمام تصاویر مربوط به دادههای کووید که مربوط به یک فرد یا Id هستند باید استخراج شوند. سپس در یک لیست جداگانه ذخیره شوند. زمانی که تمام تصاویر مربوط به یک بیمار را ذخیره کردیم، آن لیست را به لیست بزرگتری الحاق میکنیم. تعداد المانهای این لیستِ بزرگتر ، تعداد افراد یا Idهایی است که به کووید مبتلا هستند. برای این کار مینویسیم:
p_id = 0
cov_fn = []
allfiles = []
for (i, row) in df.iterrows():
n_id = row["patientid"]
if n_id != p_id and len(cov_fn)>0 and p_id != 0:
allfiles.append(cov_fn)
cov_fn = []
if row["finding"] == "COVID-19" and row["view"] == "PA":
cov_fn.append(row["filename"])
p_id = row["patientid"]
تمامی Idها را با تصاویر مربوط به آنها در allfiles ذخیره کردیم. حالا میخواهیم بر اساس Id، دادهها را به test و train تقسیم کنیم. برای این کار از کتابخانه SKLEARN و دستور train_test_split استفاده میکنیم:
from sklearn.model_selection import train_test_split
x_train_c, x_test_c = train_test_split(allfiles, test_size=0.20, random_state=23)
حالا دادههای train و test را در پوشههای مخصوص به خودشان ذخیره میکنیم:
import shutil
for img in sum(x_train_c, []):
src = '/content/covid-chestxray-dataset/images/' + img
dst = '/content/dataset/train/covid/' + img
shutil.copy2(src, dst)
for img in sum(x_test_c, []):
src = '/content/covid-chestxray-dataset/images/' + img
dst = '/content/dataset/test/covid/' + img
shutil.copy2(src, dst)
-
توضیح دستور train_test_split
معمولا در پایگاه دادههای معروف مجموعه داده آموزش (train)، ارزیابی (test) و حتی اعتبارسنجی (validation) به صورت جداگانه وجود دارند. اما در پایگاه داده ما این تقسیمبندی وجود نداشت و ما خودمان این کار را انجام دادیم. یکی از معروفترین ابزارها برای جدا کردن داده برای تست، کتابخانه SKLEARN است. در ماژول sklearn.model_selection دستوری به نام train_test_split وجود دارد که ما به شکل زیر از آن استفاده کردیم:
x_train_c, x_test_c = train_test_split(allfiles, test_size=0.20, random_state=23)
معمولا دادهها با برچسب به این دستور داده میشود. اما این دستور در واقع هر دادهای را میتواند تقسیم کند! توسط test_size مشخص میکنیم که چند درصد از دادهها را برای تست میخواهیم جدا کنیم. در نهایت هم از random_state استفاده میکنیم.
دستور train_test_split به صورت پیشفرض دادهها را بهم میریزد. یعنی دادهها را shuffle میکند. استفاده از random_state در واقع shuffle شدن دادهها را کنترل میکند. به عبارت دیگر، استفاده از این پارامتر اطمینان میدهد که هرکسی کد شما را مجدداً اجرا کند، دقیقاً همان خروجیهایی که شما دارید را دریافت میکند.
خب، حالا نوبت اضافه کردن تصاویر CT سالم است. برویم سراغ بخش بعدی …
انتخاب دادههای CT نرمال از Kaggle
در بخش قبل از پست « تشخیص کرونا با یادگیری عمیق »، دادههای کووید-19 را جدا کردیم. حالا نوبت به جدا کردن دادههای نرمال است. در دیتاست Chest X-Ray Images تعداد 5863 تصویر CT وجود دارد. ما از این تعداد فقط 201 تصویر با برچسب سالم میخواهیم! این 201 تصویر را به صورت تصادفی از دادههای آموزش انتخاب میکنیم. برای این کار ابتدا دادهها را دانلود کردیم. سپس به صورت تصادفی و به تعداد دادههای آموزش و تست، از این تصاویر انتخاب میکنیم. هرکدام را در پوشه مربوط به خودش ذخیره میکنیم:
import os
import cv2
import random
n_samples = 201
kaggle_data_path = '/content/chest_xray/train/NORMAL/'
output_path_train = '/content/dataset/train/normal/'
output_path_test = '/content/dataset/test/normal/'
filenames = os.listdir(kaggle_data_path)
random.seed(42)
filenames = random.sample(filenames, n_samples )
for i in range(n_samples):
n_image = cv2.imread(kaggle_data_path + filenames[i])
if i < 165:
cv2.imwrite(output_path_train + filenames[i], n_image)
else:
cv2.imwrite(output_path_test + filenames[i], n_image)
خب حالا ما یک پایگاه داده درست کردیم و میتوانیم از آن برای تشخیص کرونا با یادگیری عمیق استفاده کنیم.
پیش پردازش داده ها
در بخش قبل از « تشخیص کرونا با یادگیری عمیق »، یک پایگاه داده ساختیم. حالا از این دادهها استفاده میکنیم تا کرونا را تشخیص دهیم.
-
خواندن داده های CT قفسه سینه
برای پیش پردازش دادههای سی تی اسکنِ سینه، ابتدا باید دادهها را بخوانیم! برای این کار ابتدا کتابخانه os را import میکنیم. سپس با کمک os.listdir تمام فایلهایی که در مسیر دادههای نرمال و کووید-19 هستند را لیست میکنیم. حالا میتوانیم در این لیست حلقه بزنیم و یکی یکی تصاویر را با opencv و دستور cv2.imread بخوانیم! به کد زیر نگاه کنید:
import os
import numpy as np
path = "/content/dataset"
x_train_n = []
x_train_c = []
x_test_n = []
x_test_c = []
for p in os.listdir(path+ '/train/normal/'):
x_train_n.append(cv2.imread(path + '/train/normal/' + p))
for p in os.listdir(path+ '/train/covid/'):
x_train_c.append(cv2.imread(path + '/train/covid/' + p))
for p in os.listdir(path+ '/test/normal/'):
x_test_n.append(cv2.imread(path + '/test/normal/' + p))
for p in os.listdir(path+ '/test/covid/'):
x_test_c.append(cv2.imread(path + '/test/covid/' + p))
با اجرای این کد 4 لیست خواهیم داشت که عبارتند از : x_train_n (دادههای آموزش که نرمال هستند)، x_train_c (دادههای آموزش که مبتلا به کرونا هستند)، x_test_n (دادههای تست که نرمال هستند) و x_test_c (دادههای تست که مبتلا به کرونا هستند).
-
تغییر ابعاد تصاویر CT سینه
پس از اینکه دادهها را خواندیم نیاز به این داریم که ابعاد همه تصاویر را به 224×224 تغییر دهیم. فکر میکنید چرا باید انقدر برنامهریزی شده عمل کنیم؟ چرا باید ابعاد همه تصاویر دقیقا 224×224 شوند؟ شاید خیلی از شماها با دیدن عدد 224 حدس زدید که اوضاع از چه قرار است. بله، دلیل این تغییراتی که میخواهیم انجام دهیم شبکه VGG است!
ما میخواهیم از شبکه VGG استفاده کنیم. همانطور که میدانید ابعاد تصاویر ورودی در شبکه VGG، برابر با 224×224 است. بنابراین ما هم باید تمامی تصاویرمان را به 224×224 ریسایز کنیم:
for i in range(len(x_train_n)):
x_train_n[i] = cv2.resize(x_train_n[i], (224, 224))
x_train_c[i] = cv2.resize(x_train_c[i], (224, 224))
for i in range(len(x_test_n)):
x_test_n[i] = cv2.resize(x_test_n[i], (224, 224))
x_test_c[i] = cv2.resize(x_test_c[i], (224, 224))
این متغیرها از نوع لیست هستند. برای اینکه کار با این دادهها برایمان راحتتر باشد تمام 4 متغیر را به numpy-array تبدیل میکنیم:
x_train_n = np.array(x_train_n) x_train_c = np.array(x_train_c) x_test_n = np.array(x_test_n) x_test_c = np.array(x_test_c)
خب حالا ببینیم چه تغییری حاصل شد:
print(x_train_n.shape) print(x_train_c.shape) print(x_test_n.shape) print(x_test_c.shape)
با اجرای کد بالا خواهیم داشت:
(164, 224, 224, 3) (164, 224, 224, 3) (37, 224, 224, 3) (37, 224, 224, 3)
مشاهده میکنید که تصاویر همگی ابعاد 224×224 و 3 کانال دارند. پس تا اینجا کارمان را درست انجام دادهایم.
-
تلفیق دو داده کووید و نرمال و تغییر رنج تصاویر
حالا تمامی دادهها را به هم میچسبانیم. برای این کار از numpy کمک میگیریم. همینجا هم تمام دادهها را بر 255 تقسیم میکنیم تا رنج دادهها بین صفر و یک شود:
x_train = np.concatenate((x_train_n, x_train_c))/255.0 x_test = np.concatenate((x_test_n, x_test_c))/255.0
-
برچسبگذاری دادهها
تا اینجا دادههای ما برای ورود به شبکه آمادهاند. اما یک چیزی کم است! برچسب نداریم. برچسب زدن این دادهها ساده است. هر تصویر یا کووید-19 هست و یا سالم است. پس دو حالت داریم، یعنی برچسبها یا صفر هستند و یا یک. بنابراین ما برچسب دادههای سالم را صفر و دادههای کووید را یک درنظر میگیریم. این کار را به سادگی با نامپای و دستورهای zeros و ones انجام میدهیم.
y_train_n = np.zeros(x_train_n.shape[0]) y_train_c = np.ones(x_train_c.shape[0]) y_test_n = np.zeros(x_test_n.shape[0]) y_test_c = np.ones(x_test_c.shape[0])
سپس هردو برچسب صفر و یک را به هم میچسبانیم. دقت کنید که ترتیب چسباندن برچسبها باید مشابه با تصاویر باشد. یعنی ما در بخش بالا ابتدا تصاویر نرمال را گذاشتیم بعد کووید را. پس در بخش برچسبها نیز باید همین ترتیب را رعایت کنیم!
y_train = np.concatenate((y_train_n, y_train_c)) y_test = np.concatenate((y_test_n, y_test_c))
ابعاد برچسبها را هم باید تغییر دهیم. دلیل تغییر بُعد این است که تابع اتلافی که استفاده خواهیم کرد، اینطور میخواهد!
y_train = np.expand_dims(y_train, -1) y_test = np.expand_dims(y_test, -1)
-
دادهسازی یا Data Augmentation
دادهسازی یکی از راههای افزایش تعداد دادهها به صورت مصنوعی است. همه ما میدانیم که الگوریتمهای یادگیری عمیق، Data-Hungry هستند! یعنی از داده سیر نمیشوند. بنابراین اگر دادهسازی به صورت درست و اصولی انجام شود، میتواند کمک کننده باشد. ما این کار را با ImageDataGenerator کراس انجام خواهیم داد که بسیار هم ساده است. ما میخواهیم چرخش تا 15 درجه را به دادهها اضافه کنیم. برای این کار به سادگی مینویسیم:
trainAug = ImageDataGenerator(rotation_range=15, fill_mode="nearest")
خب حالا دیگر هیچ کم و کسری نداریم. برویم سراغ تعریف مدل …
تعریف مدل یادگیری عمیق برای تشخیص کرونا

ما میخواهیم برای تشخیص کرونا با یادگیری عمیق ، از شبکه VGG-16 کمک بگیریم. شبکه VGG ، یک شبکه عمیق با پارامترهای بسیار زیاد است. معماری شبکه VGG در تصویر بالا آورده شده است. در این پست ما جزئیات شبکه VGG را بررسی نخواهیم کرد. برای کسب اطلاعات بیشتر درباره VGG اینجا کلیک کنید. این شبکه 130 میلیون پارامتر دارد. نترسید! ما قرار نیست همه این پارامترها را حین آموزش پیدا کنیم. ما میخواهیم از وزنهای آموزش دیده VGG روی پایگاه داده ImageNet استفاده کنیم. یعنی در واقع از یادگیری انتقالی استفاده خواهیم کرد. اگر با مفهوم یادگیری انتقالی آشنا نیستید اینجا کلیک کنید.
برای استفاده از مدل آموزش دیده VGG-16 نیاز نیست خودمان آن را تعریف کرده و بعد روی ImageNet آموزشش دهیم. با کمک تنسورفلو 2 و کراس میتوانیم شبکه VGG-16 را با وزنهایش تنها با یک خط کد فراخوانی کنیم:
from tensorflow.keras.applications import VGG16 baseModel = VGG16(weights="imagenet", include_top=False, input_tensor=Input(shape=(224, 224, 3)))
مشاهده میکنید که ابتدا باید VGG16 را از کتابخانه tensorflow.keras.applications فراخوانی کنیم. سپس میتوانیم از آن استفاده کرده و شبکه را تعریف کنیم. اولین ورودی دستور VGG16 مشخص میکند که وزنها باید وزنهای ImageNet باشند. به سادگی این کار با عبارت weights=”imagenet” انجام شده است. ورودی دوم عبارت include_top=False است. این عبارت یعنی اینکه لایههای FC را حذف کن.
چرا این کار انجام میشود؟ مسئله ما با مسئله ImageNet متفاوت است. مسئله ما دو کلاس دارد، اما ImageNet تعداد 1000 کلاس دارد! پس نه این که نمیخواهیم لایههای FC را داشته باشیم، بلکه اصلا نمیتوانیم این کار را بکنیم. ورودی بعدی نیز ابعاد ورودی شبکه را تعیین میکند. که ما آن را به صورت (input_tensor=Input(shape=(224, 224, 3 تعریف کردیم.
اما ما نمیخواهیم همه پارامترها را آموزش دهیم! برای اینکار باید به اصطلاح لایههای VGG را فریز کنیم. فریز کردن یک لایه یعنی اینکه توانایی آموزش دیدن را از آن لایه بگیریم. ما این کار را برای همه لایههای VGG انجام خواهیم داد. در این صورت کل شبکه VGG در فرآیند آموزش شرکت نخواهد کرد. در این صورت شبکه VGG تنها ویژگیها را استخراج میکند. برای فریز کردن لایههای VGG باید بنویسیم:
for layer in baseModel.layers:
layer.trainable = False
خب حالا دو لایه Fully Connected دیگر اضافه میکنیم. برای اینکار کافی است بنویسیم:
headModel = AveragePooling2D(pool_size=(4, 4))(baseModel.output) headModel = Flatten(name="flatten")(headModel) headModel = Dense(64, activation="relu")(headModel) headModel = Dropout(0.5)(headModel) headModel = Dense(1, activation="softmax")(headModel) model = Model(inputs=baseModel.input, outputs=headModel)
مدلی که تعریف کردیم، 14,747,585 پارامتر دارد. از بین این پارامترها تنها 32,897 پارامتر قابل آموزش هستند. این مسئله را میتوانید با دستور model.summary() چک کنید!
آموزش مدل با داده های سی تی اسکن ریه
پس از تعریف مدل نیاز است آن را کامپایل کرده و سپس آموزشش دهیم. اما قبل از این کار یکسری مقادیر را باید مشخص کنیم. نرخ یادگیری را 0.001، اندازه batch را 8 و تعداد epochها را 50 در نظر میگیریم. ابتدا optimizer را تعریف میکنیم. بهینهسازی که میخواهیم از آن استفاده کنیم Adam است. همچنین میخواهیم از LearningRateDecay استفاده کنیم. یعنی نمیخواهیم نرخ یادگیری ثابت باشد. بلکه میخواهیم بعد از گذشتن تعداد epochهای مشخص، مقداری از نرخ یادگیری کم شود. برای این کار مینویسیم:
INIT_LR = 1e-3 EPOCHS = 50 BS = 8 opt = Adam(lr=INIT_LR, decay=INIT_LR / EPOCHS)
بهینهساز را تعریف کردیم، میماند اتلاف. اتلاف را BinaryCrossEntropy در نظر میگیریم و متریک را نیز Accuracy در نظر میگیریم:
model.compile(loss="binary_crossentropy", optimizer=opt, metrics=["accuracy"])
حالا از fit.generator برای آموزش مدلی که تعریف کردیم، استفاده میکنیم:
# compile our model
print("[INFO] compiling model...")
opt = Adam(lr=INIT_LR, decay=INIT_LR / EPOCHS)
model.compile(loss="binary_crossentropy", optimizer=opt,
metrics=["accuracy"])
# train the head of the network
print("[INFO] training head...")
H = model.fit_generator(
trainAug.flow(x_train, y_train, batch_size=BS),
steps_per_epoch=len(x_train) // BS,
validation_data=(x_test, y_test),
validation_steps=len(x_test) // BS,
epochs=EPOCHS)
با اجرای کد بالا خواهیم داشت:
[INFO] compiling model... [INFO] training head... Epoch 1/50 41/41 [==============================] - 7s 167ms/step - loss: 0.6297 - accuracy: 0.6280 - val_loss: 0.4909 - val_accuracy: 0.7838 Epoch 2/50 41/41 [==============================] - 7s 160ms/step - loss: 0.4158 - accuracy: 0.8933 - val_loss: 0.3781 - val_accuracy: 0.8649 Epoch 3/50 41/41 [==============================] - 7s 160ms/step - loss: 0.3295 - accuracy: 0.9116 - val_loss: 0.2557 - val_accuracy: 0.9865 Epoch 4/50 41/41 [==============================] - 7s 160ms/step - loss: 0.2604 - accuracy: 0.9299 - val_loss: 0.2009 - val_accuracy: 0.9865 . . . Epoch 46/50 41/41 [==============================] - 7s 161ms/step - loss: 0.0237 - accuracy: 0.9909 - val_loss: 0.0442 - val_accuracy: 0.9730 Epoch 47/50 41/41 [==============================] - 7s 159ms/step - loss: 0.0272 - accuracy: 0.9939 - val_loss: 0.0751 - val_accuracy: 0.9459 Epoch 48/50 41/41 [==============================] - 7s 160ms/step - loss: 0.0368 - accuracy: 0.9909 - val_loss: 0.0736 - val_accuracy: 0.9459 Epoch 49/50 41/41 [==============================] - 7s 160ms/step - loss: 0.0268 - accuracy: 0.9939 - val_loss: 0.0438 - val_accuracy: 0.9730 Epoch 50/50 41/41 [==============================] - 7s 159ms/step - loss: 0.0293 - accuracy: 0.9878 - val_loss: 0.0492 - val_accuracy: 0.9730
تا اینجا مدل را آموزش دادیم. حالا باید ببینیم مدل روی دادههای تست چه نتیجهای دارد و ماتریس اختلاط را برای نتایج تشکیل میدهیم. برویم سراغ بخش بعدی …
نتایج شبکه برای تشخیص کرونا
ابتدا باید ببینیم شبکه برای دادههای تست چه نتیجههایی میدهد. برای این کار کافی است از دستور model.predict استفاده کنیم:
preds = model.predict(x_test) print(preds)
با اجرای دستور بالا خواهیم داشت:
array([[2.5238751e-05],
[2.1423430e-04],
[1.0032668e-02],
[6.3898345e-04],
[7.1908743e-04],
[1.0135097e-03],
[1.3304194e-03],
[8.3988089e-06],
.
.
.
[9.9579775e-01],
[9.9832147e-01],
[9.9011993e-01],
[9.9960119e-01],
[9.9657273e-01],
[9.9427301e-01],
[9.9976939e-01],
[9.9892682e-01],
[9.9984610e-01],
[9.9955493e-01]], dtype=float32)
میبینید که خروجیها اعدادی بین صفر و یک هستند. اما ما یک جواب درست و درمان میخواهیم. یعنی چه؟ یعنی اینکه جواب یا صفر باشد یا یک. یعنی یا سالم یا کووید-19. به این منظور از آستانه گذاری استفاده میکنیم. ما میتوانیم به سادهترین شکل ممکن، مقدار آستانه را 0.5 درنظر بگیریم.
preds[preds > 0.5] = 1 preds[preds < 0.5] = 0
حالا که نتایج را به صفر و یک تبدیل کردیم، باید مقادیر پیشبینی شده را با برچسب مقایسه کرده و نتیجه را ارزیابی کنیم.
ماتریس اختلاط برای ارزیابی عملکرد شبکه
یکی از راههای ارزیابی عملکرد شبکه در مسائل کلاسبندی، استفاده از ماتریس اختلاط است. برای ساختن ماتریس اختلاط باز هم میتوانیم از ScikitLearn استفاده کنیم. به این منظور از sklearn.metrics دستور confusion_matrix را فراخوانی کنیم:
from sklearn.metrics import confusion_matrix cm = confusion_matrix(x_test, preds)
حالا با استفاده از ماتریس اختلاط میتوانیم مقدار Accuracy، Sensitivity و Specificity را محاسبه کنیم.
cm = confusion_matrix(y_test, preds)
total = sum(sum(cm))
acc = (cm[0, 0] + cm[1, 1]) / total
sensitivity = cm[0, 0] / (cm[0, 0] + cm[0, 1])
specificity = cm[1, 1] / (cm[1, 0] + cm[1, 1])
print('accuracy: ', acc)
print('confusion matrix: ', '\n', cm)
print('sensitivity: ', sensitivity)
print('specificity: ', specificity)
با اجرای کد بالا خواهیم داشت:
accuracy: 0.972972972972973 confusion matrix: [[35 2] [ 0 37]] sensitivity: 0.9459459459459459 specificity: 1.0
مشاهده میکنید که دقت 97 درصد بهدست آمد. مقدار sensitivity برابر با 94 درصد و specificity برابر با 100 درصد بهدست آمد. اما یک سوال. آیا 0.5 بهترین مقدار آستانهای است که میتوانیم تعریف کنیم؟؟ آیا بهتر نیست چند مقدار آستانه را امتحان کنیم و آن مقداری که نتیجه بهتری دارد را انتخاب کنیم؟ به این منظور کافی است بنویسیم:
th = np.linspace(0.2, 0.8, 7)
all_cms = []
all_sens = []
all_spec = []
all_acc = []
for t in th:
preds = model.predict(x_test)
preds[preds > t] = 1
preds[preds < t] = 0
cm = confusion_matrix(y_test, preds)
total = sum(sum(cm))
acc = (cm[0, 0] + cm[1, 1]) / total
all_acc.append(acc)
sensitivity = cm[0, 0] / (cm[0, 0] + cm[0, 1])
specificity = cm[1, 1] / (cm[1, 0] + cm[1, 1])
all_cms.append(cm)
all_sens.append(sensitivity)
all_spec.append(specificity)
print('best accuracy: ', all_acc[np.argmax(all_acc)])
print('threshold: ', th[np.argmax(all_acc)])
print('confusion matrix: ', '\n', all_cms[np.argmax(all_acc)])
print('sensitivity: ', all_sens[np.argmax(all_acc)])
print('specificity: ', all_spec[np.argmax(all_acc)])
با اجرای کد بالا خواهیم داشت:
best accuracy: 1.0 threshold: 0.7000000000000002 confusion matrix: [[37 0] [ 0 37]] sensitivity: 1.0 specificity: 1.0
مشاهده میکنید که بهترین نتیجه مربوط به آستانه 0.7 است. با این مقدار آستانه مقادیر accuracy، sensitivity و specificity برابر با 100 درصد بهدست آمد. تبریک!
منبع
این پست با الهام از پست «تشخیص کووید-19 در تصاویر X-Ray» از آقای آدریان نوشته شده است. در این پستِ آقای آدریان، یک اشتباه بسیار بد وجود دارد! ایشان تعداد 25 داده کووید-19 ارائه کردهاند. با نگاهی به نام این تصاویر مشخص میشود که در بعضی موارد، چند تصویر مربوط به یک بیمار است. سپس دادهها به صورت تصادفی به test و train تقسیم شده است!! این یعنی ممکن است بعضی از تصاویرِ یک شخص در داده train و برخی دیگر در test بیفتد. یعنی ما با این کار به شبکه تقلب رساندهایم. و این یک اشتباه بسیار بزرگ است. در پست « تشخیص کرونا با یادگیری عمیق »، این مشکل به طور کامل رفع شده است.
در پست « تشخیص کرونا با یادگیری عمیق » ما توانستیم با استفاده از تصاویر سی تی اسکن ریه، کووید-19 را تشخیص دهیم. امیدوارم این آموزش مورد توجه شما قرار گرفته باشد. نظرات و سوالات خود را پایین 👇 برایمان کامنت کنید. حتما سوالات شما پاسخ داده خواهد شد.
مطالب زیر را حتما مطالعه کنید

LLM Research یا LLM Engineering؟ راهنمای یادگیری مدلهای زبانی بزرگ
یادگیری انتقالی

شبکه VGG

مهندسی پرامپت

مدل nanoGPT

شگفتانگیزترین ایده هوش مصنوعی از نظر Andrej Karpathy
10 دیدگاه
به گفتگوی ما بپیوندید و دیدگاه خود را با ما در میان بگذارید.
سلام وقت بخیر
امکان دانلود فایل metadata.csvبرای من وجود نداره.روشی برای دانلودش وجود داره؟
با سلام در اجرای این کد چرا این پیغام خطا دریافت می کنم؟
—————————————————————————
IndexError Traceback (most recent call last)
in
1 for i in range(len(x_train_n)):
2 x_train_n[i] = cv2.resize(x_train_n[i], (224, 224))
—-> 3 x_train_c[i] = cv2.resize(x_train_c[i], (224, 224))
4
5 for i in range(len(x_test_n)):
IndexError: list index out of range
به جای مقایسه با COVID-19 باید با Pneumonia/Viral/COVID-19 مقایسه شود.
سلام،
بله درسته.
دیتاست مربوط به covid مدام تغییر میکنه، بنابراین نیاز هست تغییرات جزئی در کدها اعمال بشه.
موفق باشید 🌹
با این کد
(164, 224, 224, 3)
(164, 224, 224, 3)
(37, 224, 224, 3)
(37, 224, 224, 3)
نداریم و بجایش
(165,)
(150, 224, 224, 3)
(36, 224, 224, 3)
(46,)
برای من بدست می آید
علتش را میفرمایید؟
allfiles مقدار نمیگیرد.
خیلی خوب ایا برای شبکه های عمیق دیگر باید کدی مجزا نوشت یا همه شبکه های عمیق به همین صورت کد انها نوشته میشود
سلام،
منظورتون رو درست متوجه نشدم. اگر منظورتون این هست که به جای VGG میتونید از شبکههای دیگه استفاده کنید؟ جواب بله هست ولی خب طبیعتا بسته به ساختار شبکه، ممکن هست نیاز باشه توی ابعاد ورودیها و لایه آخر کمی تغییرات بدید.
خیلی خوب بود
ممنون.
سپاس🌹