
شبکه عصبی کانولوشن
بهنام خدا، سلام… در این پست میخواهم به آموزش شبکه عصبی کانولوشن بپردازم. دراینجا صرفا شبکه عصبی کانولوشن را توضیح دادهام. در این آموزش شبکه کانولوشن را برای موضوع طبقه بندی توضیح دادهام. امیدوارم با این آموزش دوستی خوبی بین شما و شبکه کانولوشنی شکل بگیرد. بسیارخب، با CNN چیست شروع میکنیم. با هوسم همراه باشید…
شبکه عصبی کانولوشن چیست؟ سادهتر بگوییم CNN چیست و خلاص!
از زمان پیدایش یادگیری عمیق (Deep Learning)، شبکه عصبی کانولوشن (Convolutional Neural Network) گل سرسبد ایدهها در یادگیری عمیق بوده است. به شبکه کانولوشن به اختصار CNN یا ConvNet گفته میشود. شبکه CNN در سال 1990 با الهامگیری از آزمایشهای انجامشده توسط Hubel و Wiesel روی قشر بینایی (Visual Cortex) معرفی شد. یکی از اولین پروژههای انجامشده با این شبکه CNN، پروژه معروف شناسایی ارقام دستنویس MNIST در سال 1998 توسط Yann Lecun بود که نتایج امیدوارکنندهای به همراه داشت.

گرد و خاک بهپا کردن شبکه عصبی کانولوشن
اما درخشش اصلی شبکه کانولوشن در سال 2012 در جریان رویداد “ImageNet Large Scale Recognition Challenge” (همان مسابقه ImageNet) اتفاق افتاد. اتفاقی که توجه جامعه محققین را به خود جلب کرد. در مسابقه ImageNet سال 2012، Alex Krizhevsky از دانشگاه تورنتو با شبکه AlexNet وارد مسابقه پیچیده ImageNet شد. مسابقه ImageNet یک چالش دستهبندی (Classification) با 1.2 میلیون تصویر در 1000 کلاس بود. شبکه AlexNet با خطای 16.4٪ به رتبه اول مسابقه رسید. به نظر شما نفر دوم به چه خطایی دست یافته بود؟ 26.2%! اختلاف خطای حداقل 10 درصدی بین شبکه CNN با سایر روشها…
با این نتیجه، AlexNet مشت محکمی بر میز کوبید و نقشه راه جدیدی در بینایی کامپیوتر ترسیم کرد. از آن زمان تا امروز (2020)، تحقیقات CNN رشد چشمگیری داشته است. تنها در 3 سال، محققان از 8 لایه AlexNet به 152 لایه ResNet رسیدند و میزان خطای چالش ImageNet را به کمتر از 4٪ کاهش دادند. 12% کاهش خطا طی 3 سال با شبکه CNN، البته با افزایش پیچیدگی ساختار شبکه CNN!

طوفان شبکه کانولوشن
سرعت رشد شبکه کانولوشنی آنقدر زیاد بود که در مدت کوتاهی، در بسیاری از زمینههای مشکلِ بینایی کامپیوتر مانند شناسایی عمل انسان، تشخیص اشیا، شناسایی چهره و ردیابی انقلابی برپا کرد. با سیطره بر بینایی کامپیوتر، شبکه کانولوشنی در سایر زمینههای هوش مصنوعی مانند پردازش زبان و گفتار نیز وارد شد و اتفاقا نتایج خوبی هم بدست آورد. مثلا، گوگل با استفاده از شبکه کانولوشن در یادگیری تقویتی، مدل AlphaGo را ساخت که توانست بهترین بازیکن بازی سخت Go را قدرتمندانه شکست دهد و در سرتیتر اخبار قرار گیرد. شبکه عصبی کانولوشن همچون مارکوپولو وارد قلمروهای مختلف شد و حتی در حوزه پزشکی نیز به دستاوردهای قابل اعتنایی دست یافت. با این دستاوردها، شبکه CNN فرزند خلف یادگیری عمیق بود که باعث شد یادگیری عمیق به شهرتی روزافزون دست یابد.

بعد از جواب به سوال “شبکه عصبی کانولوشن چیست؟”، میخواهم کمی شما را با شبکه کانولوشن آشنا کنم. در بخش بعدی، خیلی وارد جزئیات نمیشوم، اما رفته رفته تا آخر این پست به جزئیات شبکه CNN هم خواهیم رسید.
آشنایی با شبکه عصبی کانولوشن
شبکه عصبی کانولوشن همانند سایر شبکه های عصبی (مثلا شبکه عصبی MLP) از لایههای نورونی با وزن و بایاس با قابلیت یادگیری تشکیل شده است. قطعا میدانید که در هر نورون اتفاقات زیر رخ میدهد:
- نورون مجموعهای ورودی دریافت میکند.
- ضرب داخلی بین وزنهای نورون و ورودیها انجام میشود.
- حاصل با بایاس جمع میشود.
- درنهایت، از یک تابع غیرخطی (همان activation function) عبور داده میشود.

فرآیند بالا لایه به لایه انجام میشود و درنهایت به لایه خروجی میرسیم. لایه خروجی، پیشبینی شبکه را تولید میکند. اما با این حد از تشابه بین شبکه MLP و شبکه CNN، پس تفاوت در کجاست؟ در ادامه به این سوال مهم جواب میدهم…
تفاوت شبکه عصبی MLP و کانولوشن
تفاوت در ورودی است، مثلا تصویر… تصاویر معمولا به شکل یک ماتریس دوبعدی از اعداد نمایش داده میشوند. هر درایه در این ماتریس دوبعدی معادل با یک پیکسل هست. در بخش بعدی درمورد تصویر بیشتر توضیح خواهم داد. اگر یک تصویر 100×100 داشته باشیم، یعنی 10000 پیکسل داریم که به صورت دوبعدی بهصورت مسالمتآمیز کنار همدیگر نشستهاند. حال تصور کنید بخواهیم یک لایه ورودی برای این 10000 پیکسل بسازیم؛ باید 10000 نورون برای لایه ورودی شبکه MLP درنظر بگیریم. اضافه کردن نورون و لایه بیشتر به این شبکه MLP باعث میشود شبکه ما شامل حجم بزرگی از پارامترها شود، محاسباتش هزینهبر باشد و البته Overfitting اتفاق بیفتد.

حالا نقطه قوت شبکه CNN کجاست؟
این شبکهها بهگونهای طراحی شدهاند که برای ورودیهای با ساختار ماتریسی (دوبعدی و سهبعدی) بهخوبی کار میکنند. شبکه MLP، ساختار دادههای ورودی را عوض میکند و یک ماتریس دوبعدی 100×100 را تبدیل به یک بردار به ابعاد 10000 میکند. اما شبکه CNN ساختار ورودی را عوض نمیکند و به ارتباط بین پیکسلهای همسایه اهمیت میدهد.
چرا باید به ارتباط به پیکسلهای همسایه اهمیت دهیم؟ به تصویر زیر نگاه کنید؛ مگر نهاینکه از کنارهم قرار گرفتن تعدادی پیکسل در راستای سطر و ستون یک تصویر از پاندای خسته تشکیل شده است؟ بنابراین، مهم است که ساختار تصویر یا ورودی را عوض نکنیم (تبدیل به بردار نکنیم) و همان ورودی اصلی را به شبکه بدهیم. دقیقا همان کاری که شبکه CNN انجام میدهد.

آیا شبکه CNN تنها برای تصویر دوبعدی مناسب است؟ خیر، دادههای زیر غذای خوشمزهای برای شبکه CNN هستند:
- دادههای یک بعدی: سیگنال و sequence (مثلا یک sequence از کلمات)
- دادههای دوبعدی: تصویر و طیف (spectogram) صوت
- دادههای سه بعدی: ویدئو و تصاویر حجمی (مثلا تصاویر MRI)
- دادههای چهاربعدی: تصاویر حجمی همراه با زمان (مانند fMRI)
بعد از آشنایی با مزایای شبکه کانولوشن و بررسی تفاوتش با شبکه MLP، وقتش رسیده که معماری این شبکه را زیر تیغ جراحی ببریم. اما بیایید اول یک آشنایی کلی با معماری شبکه CNN بدست آوریم.
یک معماری ساده از معماری شبکه عصبی کانولوشن
در شکل 7 یک مثال ساده از معماری شبکه عصبی کانولوشن نشان داده شده است. شبکه کانولوشن معمولا از بلوکهای مختلفی تشکیل شده است. لایهها یا بلوکهای مختلف در شبکه CNN عبارتنداز:
- لایه ورودی (Input layer) [بلوک زرد در شکل 7]
- لایه کانولوشن (Convolutional layer) [بلوکهای آبی در شکل 7]
- لایه غیرخطی (Non-linear activation function) [بلوکهای آبی در شکل 7] (معمولا تابع غیرخطی را همراه با لایه کانولوشنی یکجا نشان میدهند)
- لایه پولینگ (Pooling layer) [بلوکهای قرمز در شکل 7]
- لایه فولی کانکتد (Fully connected layer) [بلوکهای سبز در شکل 7]
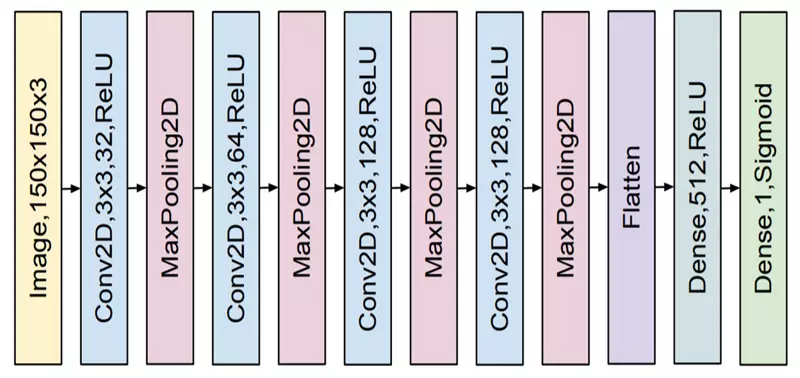
در ادامه این پستِ آموزشِ شبکه عصبی کانولوشن، لایههای بالا را توضیح میدهم. شاید بگویید که لایه ورودی که صرفا تصویر است و جز لایههای شبکه محسوب نمیشود. اما، من لایه ورودی را هم اضافه کردم و لازم هست درباره آن توضیح دهم. پس، ابتدا ورودی را بررسی میکنیم، سپس به لایههای شبکه کانولوشن میرسیم. در بالا اشاره کردم که شبکه CNN ورودیهای متنوعی را میپذیرد. اما من دراینجا میخواهم معروفترین داده ورودی به شبکه CNN، یعنی تصویر را فقط بررسی کنم.
تصویر در پردازش تصویر
در سادهترین تعریف ممکن، تصویر یک آرایه یا ماتریس دوبعدی از اعداد است که هریک از درایههای آن معادل یک پیکسل هست. در شکل 8 یک نمونه تصویر نشان داده شده است. نمایی زومشده از تصویر نیز نشان داده شده. مشاهده میکنید که چگونه مربعهای کوچک در کنارهم قرار گرفتهاند. به جدول اعداد نگاه کنید؛ اگرچه درحالت معمولی ما یک تصویر با رنگ میبینیم (تصویر سمت چپ شکل 8)، اما این اعداد هستند که این رنگها را میسازند (جدول سمت راست شکل 8)!
مقادیر موجود در تصویر یا ماتریس بین 0 تا 255 هستند. مقدار صفر معادل با رنگ سیاه مطلق و مقدار 255 معادل با رنگ سفید است. هرچقدر این مقادیر به صفر نزدیکتر باشد، آن پیکسل تیرهتر میشود. هرچقدر مقدار پیکسل به 255 نزدیکتر باشد، رنگ آن پیکسل روشنتر میشود. همانطور که در شکل 8 مشاهده میکنید، نواحی تیره در ناحیه بزرگنمایی شده (سمت چپ و پایین) مقادیر کمتری دارند (مثلا اعداد 59 61 65). همچنین نواحی روشن (سمت راست و بالا)، مقادیر بزرگتری دارند (مثلا اعداد 206 207 204).
دو نوع تصویر سطح خاکستری (Gray scale image) و تصویر رنگی (RGB image) معمولا بهعنوان ورودی به شبکه عصبی کانولوشن داده میشود.
تصویر سطح خاکستری در پردازش تصویر
سادهترین نوع تصویر، یک تصویر سطح خاکستری است. در واقع این تصویر یک ماتریس دوبعدی است. تصویر شتر در شکل 8 یک نمونه تصویر سطح خاکستری است. شتر چیه؟! زرافه هست! 😅 داشتم متن رو بعد از مدتی مرور میکردم، دیدم شاخ شمشاد رو نوشتم شتر!
تصویر رنگی در پردازش تصویر
تصاویر رنگی ساختار کمی متفاوت دارند. تصویر رنگی از سه صفحه تشکیل شده است. این صفحات عبارتنداز صفحه قرمز (R)، صفحه سبز (G) و صفحه آبی (B). مشخصات هر صفحه مشابه همان تصویر سطح خاکستری است و مقادیر اعداد بین 0 تا 255 است. از ترکیب سه عدد، یک رنگ نهایی حاصل میشود. بههمین خاطر به تصاویر رنگی، تصویر RGB گفته میشود. از ترکیب این سه صفحه، یک تصویر رنگی حاصل میشود. یک نمونه تصویر RGB در شکل 9 نشان داده شده است.

پس تصویر رنگی از سه صفحه RGB تشکیل شده است. حالا که تصویر را شناختید، میخواهم شما را با تنسور آشنا کنم. در یادگیری عمیق به وفور کلمه تنسور را میشنوید. بهصورت کوتاه در ادامه تنسور را توضیح میدهم.
تنسور چیست؟
در یادگیری عمیق، عبارت تنسور را زیاد خواهیم شنید. در گذشته همه ما با گونههای خاصی از تنسورها کار کردیم. اعداد، بردارها و ماتریسها همگی حالات خاص یک تنسور هستند! تنسورها در واقع تعمیم یافته ماتریسها هستند و میتوان آنها را به صورت یک آرایه چندبعدی نمایش داد. یعنی، به عدد، بردار و ماتریس بهترتیب تنسور صفربعدی، یک بعدی و دوبعدی گفته میشود. دقت کنید که تنسورها دقیقا همانند ماتریسها و بردارها میتوانند اندیسدهی شوند. یعنی ما با کمک اندیسدهی میتوانیم به تمامی عناصرِ یک تنسور دسترسی داشته باشیم. یک تصویر سطح خاکستری معادل با تنسور دوبعدی و تصویر رنگی معادل با تنسور سه بعدی است. البته، در یادگیری عمیق تنسور چهاربعدی هم خواهید دید! پیشنهاد میکنم بخش آشنایی با تنسور در ریاضیات را مطالعه کنید.
بسیارخب، درادامه توضیح لایههای اصلی شبکه عصبی کانولوشن را شروع میکنم. اولین لایه، لایه کانولوشنی است. پس برویم با کانولوشن آشنا شویم و بعد هم لایه کانولوشنی را زیر ذرهبین قرار دهیم…
کانولوشن چیست؟
در عملگر کانولوشن، مطابق شکل 10 چهار مولفه مهم وجود دارد که عبارتنداز:
- ماتریس یا تصویر ورودی (Input)
- فیلتر یا کرنل کانولوشنی (Convolution Filter)
- عملگر کانولوشن (*)
- ویژگی خروجی کانولوشن (Output)

خیلی ساده بخواهم عملکرد کانولوشن را توضیح دهم، باید بگویم که عملگر کانولوشن (*)، کرنل یا فیلتر کانولوشنی را برمیدارد و روی تصویر یا ماتریس ورودی میلغزاند. بهعبارتی دیگر، کرنل یا فیلتر روی تصویر حرکت میکند یا تصویر ورودی را اسکن میکند. به شکل زیر نگاه کنید؛ ماتریس آبی معادل با تصویر یا ویژگی ورودی و ماتریس قرمز معادل با فیلتر یا کرنل کانولوشنی است. به نحوه حرکت یا اسکن فیلتر روی تصویر دقت کنید. فیلتر ابتدا هرسطر را ستون به ستون طی میکند و بعد یک سطر پایین میآید و دوباره ستون به ستون جلو میرود و این فرآیند تا آخر ادامه دارد…

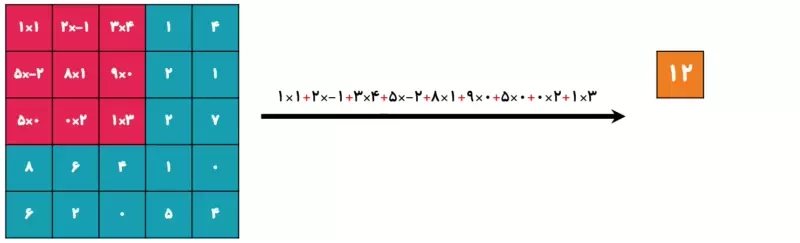
مثال عددی از کانولوشن
اما ماتریس ورودی و فیلتر بالا شامل هیچگونه عددی نیستند. حالا به تصویر زیر نگاه کنید؛ هر فیلتر کانولوشنی، شامل مجموعهای عدد است. با قرار گرفتن فیلتر روی هربخش از تصویر، اعدادِ در فیلتر درایه به درایه در پیکسلهای متناظر تصویر ضرب میشوند. درنهایت همه اعداد باهم جمع میشوند. مثلا در تصویر زیر، 9 ضرب نظیر به نظیر بین یک بخش 3×3 از ماتریس آبی با ماتریس قرمز انجام شده است. درنهایت، این 9 ضرب باید باهم به شکل زیر جمع شوند:
1×1 + 2×-1 + 3×4 + 5×-2 + 8×1 + 9×0 + 5×0 + 0×2 + 1×3 = 12

حالا این عدد 25 را کجا باید ذخیره کرد؟ فعلا مطابق شکل زیر، خروجی را در یک آرایه تنها قرار میدهیم.

حالا باید فرآیند اسکن کردن (شکل 11) و محاسبه خروجی (شکل 13) باهم ترکیب شود. یعنی فیلتر کانولوشنی سفرهای استانی را شروع کند و در هر محلی خروجی را از طریق ضرب درایه به درایه بین فیلتر و تصویر محاسبه نماید. ضربها را باهم جمع و در خروجی میچینیم. شکل زیر گویای فرآیند کامل کانولوشن است. دقت کنید، هرطوری که فیلتر حرکت میکند (مثلا یک ستون جلو میرود یا یک سطر پایین میآید)، ما هم خروجی را به همان شکل کنار هم میچینیم.
چرا سایز خروجی کانولوشن کوچک شد؟!
چرا ماتریس خروجی در شکل 14، دو سطر و ستون کمتر از ماتریس ورودی دارد؟ چرا ماتریس خروجی در شکل 14، 3×3 است اما ماتریس ورودی 5×5 است؟ چرا هماندازه نیستند؟ جواب این سوالها این است که بسته به اندازه فیلتر، اندازه ماتریس خروجی تغییر میکند. مثلا وقتی فیلتر 3×3 باشد، خروجی 2 سطر و ستون کمتر از ورودی خواهد داشت. حالا بیایید این مساله را فرموله کنیم. فرض کنید ماتریس ورودی و فیلتر مربعی باشند و سایز آنها بهترتیب برابر با n و k باشد. دراینصورت، سایز خروجی m با رابطه زیر بدست میآید:
m = n – (k-1)
به همین سادگی… حالا اگر سایز ورودی و فیلتر بهترتیب 5×5 و 3×3 باشد، اندازه خروجی برابر با 3×3 خواهد بود. آیا راهی وجود دارد که اندازه ماتریس خروجی کاهش پیدا نکند و همان 5×5 بماند؟ بله وجود دارد، تکنیکی به نام padding یا لایه گذاری ماتریس وجود دارد که به دور ماتریس ورودی سطر و ستونهایی اضافه میشود که باعث میشود جلوی کاهش بعد خروجی گرفته شود. مثلا، در شکل 14، اگر ورودی را بهنوعی جعلی به یک ماتریس 7×7 تبدیل کنیم، آنوقت خروجی 5×5 خواهد بود. یعنی اندازه خروجی برابر با همان ورودی است. دقت کنید؛ ما بهصورت جعلی ورودی را افزایش بعد میدهیم. در بخش لایه کانولوشنی راهحلش را توضیح میدهم.
قصد بررسی عمیق عملگر کانولوشن را ندارم، چون خود یک پست جداگانه و طولانی را میطلبد. اما میخواهم خیلی خلاصه درباره کارکرد کانولوشن توضیح دهم. پس بخش بعد را از دست ندهید…
کانولوشن زیر ذرهبین
بیایید چند نکته از کانولوشن را باهم مرور کنیم.
نکته اول
اعدادی که در ماتریس خروجی ذخیره میشوند، تابعی از ورودی و فیلتر هستند. چه زمانی به ازای ضرب بین فیلتر روی یک محل از تصویر، خروجی بزرگ یا کوچک میشود؟ ساده است، هروقت فیلتر با یک پنجره از تصویر خیلی شبیه هم باشند (از لحاظ عددی)، خروجی عدد بزرگی میشود. اگرهم شبیه هم نباشند، خروجی عدد کوچکی میشود. یعنی چه؟ یعنی اینکه، فیلتر به دنبال پیدا کردن نواحی مشابه خود در تصویر است و هرجایی ناحیه مشابهِ خود را پیدا کرد بلند فریاد میزند (عدد بزرگ).
پس کانولوشن منجر به یافتن الگوهای خاص در تصویر باتوجه به فیلتر میشود. اعداد موجود در فیلتر بسیار مهم هستند. به شکل 15 که یک سیگنال یک بعدی است دقت کنید. ببینید، چطور نواحی مشابه با فیلتر در خروجی آشکار شده است. دقیقا آنجایی که دو مربع روی هم قرار میگیرند، یک مقدار پیک در خروجی بهوجود میآید. یعنی شباهت در آن نقطه بسیار بالاست.

نکته دوم
ارتباط دادن عمل کانولوشن به عملکرد یک نورون است. یک نورون یک جمع وزندار (ضرب بین پارامترها و ورودی و نهایتا جمع) بود. اینجا هم همین است! فیلتر که شامل یک سری اعداد است به ورودیها وزن میدهد (ضرب درایه به درایه بین فیلتر و پنجرههای ماتریس ورودی) و نهایتا اعداد وزندهیشده ورودی را باهم جمع میکند.
نکته سوم
در نورون پارامترها متغیر بودند و از طریق فرآیند آموزش بدست میآمدند. اینجا هم اعداد موجود در فیلتر از طریق فرآیند آموزش بهدست میآیند. البته، قبل از پیدایش شبکه عصبی کانولوشن، از کانولوشن در پردازش تصویر و سیگنال بسیار زیاد استفاده میشد. اما اعداد فیلترهای کانولوشنی ثابت بودند و توسط یک متخصص این اعداد طراحی میشوند. مثلا در شکل 16 یک فیلتر لبهیابی با نتیجه خروجی را آوردهام. ببینید، فیلترها چه بلایی سر تصویر میآورند و فقط دنبال مطلوب خود هستند.

تا اینجا، به شما درباره کانولوشن تصویر دوبعدی (تصویر سطح خاکستری) توضیح دادم. اما در شبکه عصبی کانولوشن، معمولا ورودی یک تصویر رنگی (ماتریس سه بعدی) است. دراینحالت کانولوشن چگونه انجام میشود؟ بسیار ساده است…
کانولوشن با ورودی سهبعدی
همانطور که در بخش قبلی گفتم، تصویر رنگی سه کانال یا صفحه دارد. بنابراین، فیلتر شما هم باید سه کانال داشته باشد. یعنی اگر قبلا یک فیلتر 3×3 برای کانولوشن در تصویر دوبعدی داشتیم، حالا یک فیلتر 3×3×3 خواهیم داشت. چرا؟ چون هرصفحه از تصویر رنگی بهصورت مجزا برای خودش یک فیلتر دارد. به شکل 17 نگاه کنید؛ سه صفحه از فیلتر بهصورت موازی باهم روی سه صفحه از تصویر حرکت میکنند. با فرض اینکه فیلتر 5×5 باشد، در هرلحظه 25 ضرب در هرصفحه انجام میشود و درمجموع برای سه صفحه میشود 75 ضرب… درنهایت خروجی برابراست با جمع این 75 ضرب. پس درنهایت نتیجه ضرب سه صفحه باهم جمع میشود و خروجی نهایی یک تصویر 100×100×3 نیست، بلکه یک تصویر 100×100 است.

حالا مثلا مثلا مثلا، اگر ورودی بجای 3 صفحه، 10 صفحه داشته باشد، برای خروجی چه اتفاقی میافتد؟ فیلتر چه شکلی خواهد بود؟ فیلتر باید 10 صفحه داشته باشد و اگر فرضا فیلتر را 5×5 درنظر بگیریم، اندازه فیلتر به شکل 5×5×10 باشد. هریک از این 10 صفحه، در صفحه متناظر با صفحه تصویر کانوالو میشود. بعد از توضیح درباره کانولوشن، وقت آن رسیده که درباره لایه کانولوشنی در شبکه عصبی CNN توضیح بدهم. برویم سراغ بخش بعدی…
لایه کانولوشن در شبکه عصبی کانولوشن (Convolutional Layer)
هسته اصلی شبکه CNN لایه کانولوشنی است که درصد اعظم محاسبات شبکه عصبی کانولوشن را به خود اختصاص داده است. هر لایه کانولوشن در شبکه عصبی کانولوشن شامل مجموعهای فیلتر است و از کانولوشن بین فیلترها و لایه ورودی است که خروجی ساخته میشود. به خروجی لایه کانولوشنی، فیچرمپ (Feature Map) گفته میشود. میخواهم این جمله را کمی بشکافم.
چرا یک لایه کانولوشنی نیاز است؟
همانطور که بخش قبلی گفتم، یک فیلتر میتواند شامل یک الگویی خاص باشد و در تصویر به دنبال آن الگو باشد. اتفاقا در فرآیند آموزش شبکه، به دنبال این هستیم که این فیلترها الگوهای معناداری از هر تصویر استخراج کنند. مثلا، فیلتری داریم که شامل الگوی گوش گربه هست و میتواند حضور یک گربه در تصویر ورودی را تشخیص دهد. اما فقط به یک الگو بسنده کنیم؟ آیا گربه، فقط شامل یک الگوی خاص است؟ مثلا، دهان، گوشها، چشمها و دُم هرکدام الگوی خاصی از گربه نیستند؟ با یک فیلتر میشود همه این الگوها را شکار کرد؟ بهتر نیست شواهد بیشتری جمع کنیم و بعد تصمیم بگیریم؟
این همان کاری است که در لایه کانولوشنی انجام میشود. جستجو در تصویر برای یافتن تنها یک الگو منجر به نتایج خوبی نمیشود و باعث میشود شبکه از لحاظ کارایی محدود باشد. برای حل این مشکل، نیاز است که لایه کانولوشنی چندین فیلتر داشته باشد. هریک از فیلترها به تنهایی یک الگوی خاص داشته باشند و خروجی لایه کانولوشنی مجموعهای از الگوهای مختلف باشد. در شکل زیر، تصویری نشان داده شده که یک تصویر با فیلترهای مختلفی کانوالو شده و هر فیلتر هم یک خروجی جداگانه برای خود تولید کرده است. همه تصاویر مربوط به یک چهره با ماسک هست؛ اما دقت کنید که در هر تصویری یک مجموعه ویژگی خاص مورد توجه بوده است. مثلا در تصویری، لبههای افقی، در دیگری لبههای عمودی و غیره. در شکل زیر 64 فیلتر مختلف به تصویر ورودی اعمال شده است.

اما، یک لایه کانولوشنی در شبکه عصبی کانولوشن را چگونه نمایش میدهند؟ بریم ببینیم…
نمایش لایه کانولوشن
نمایش بلوک دیاگرامی شکل زیر، یک نمایش مرسوم برای لایه کانولوشنی است. حالا جزبهجز درمورد شکل 19 توضیح میدهم؛ اول، تکلیف ورودی را مشخص کنم که یک تنسور سه بعدی است. دوم، فیلترها را مشاهده میکنید. دیگر یک فیلتر نداریم بلکه یک مجموعه فیلتر داریم (دراینجا N تا فیلتر). معمولا همه فیلترها را یکجا در قالب یک تنسور چهاربعدی نمایش میدهند. از سمت چپ به راست، هریک از ابعاد موجود در فیلتر معادل با موارد زیر هستند:
- بعد اول، معادل با تعداد سطر (5)
- بعد دوم، معادل با تعداد ستون (5)
- بعد سوم، معادل با تعداد کانال (3)
- بعد چهارم، معادل با تعداد فیلتر (N)
یعنی یک تنسور چهاربعدی به ابعاد 5×5×3×N معادل با N فیلتر به ابعاد 3×5×5 است. پس قراراست روی تصویر ورودی، N فیلتر اعمال شود. شما به عنوان یک متخصص مجاز هستید که اندازه سطر و ستون و تعداد فیلترها را خودتان تعیین کنید. اما بعد سوم (تعداد کانالها)، از روی تعداد کانال ورودی تعیین میشود. چرا؟ خودتان دلیلش را بگویید، در آخر بخش قبلی توضیح دادم.
درنهایت، خروجی یک فیچرمپ است به ابعاد 100×100×N که عدد سوم برابر با تعداد فیلترهاست. چرا؟ چون هر فیلتر یک خروجی تولید میکند و با N فیلتر، ما N صفحه خواهیم داشت. بنابراین، مطابق شکل زیر خروجی یک لایه کانولوشنی یک تنسور سه بعدی خواهد بود. اگر به شکل 18 دوباره نگاه کنید، میبینید که تعداد فیلترها برابر با N=64 است و خروجی هم یک تنسور سه بعدی با 64 صفحه هست. البته، در شکل 18، این 64 صفحه بازشده و بهصورت جداگانه نمایش داده شده است.

خب، انتظار دارم با لایه کانولوشنی آشنا شده باشید. اما همواره با کانولوشن، مفاهیم یا پارامترهای مهمی مطرح میشوند که دانستن آنها ضروری است. درادامه، این پارامترها را به شما معرفی میکنم.
تعداد فیلتر در لایه کانولوشن
تعداد فیلترها، تعداد ویژگیهای تشخیص داده شده را نشان میدهد. این هایپرپارامتر معمولا نمایی از 2 (معمولا بین 32 تا 4096) انتخاب میشود. معمولا استفاده از فیلترهای بیشتر باعث ایجاد یک شبکه عصبی قدرتمندتر میشود. اما این افزایش پارامترها ممکن است باعث overfitting شود.
اندازه فیلتر در لایه کانولوشن
اندازه فیلتر معمولا به صورت مربعی (برای تصاویر) و 3×3 تعریف میشود. اما 5×5 و 7×7 نیز گاهی استفاده میشود. با فیلترهای کوچک، تعداد پارامترهای قابل یادگیری بسیار کمتر میشود.
اندازه پدینگ (padding) در لایه کانولوشن
در بخش قبل دیدید که بعد از فیلتر کردن یک ماتریس 5×5 با فیلتر 3×3، سایز خروجی دو سطر و ستون کمتر از ماتریس ورودی داشت. گفتیم که با لایه گذاری یا padding میتوانیم به صورت جعلی اندازه ورودی را افزایش دهیم تا ماتریس خروجی هماندازه ماتریس ورودی بشود. درمورد لایه گذاری صحبت بسیار است و معمولا در پردازش تصویر بررسی میشود. اما یک راه ساده و رایج آن اضافه کردن سطر و ستون صفر بهصورت متقارن به دور ماتریس ورودی است. به لایه گذاری صفر zero padding گفته میشود. به شکل 20 نگاه کنید که چگونه یک لایه صفر دور ماتریس قرار گرفته است. حالا فیلتر کانولوشنی ما فضای بیشتر برای گام برداشتن و اسکن کردن دارد و طبیعتا خروجی هم بزرگتر میشود.

تمرین: علامتهای سوال شکل بالا را پر کنید!
از کجا بفهمیم چه تعداد لایه باید دور ماتریس اضافه کرد؟ بستگی به اندازه فیلتر دارد؛ قبلا هم گفته بودم که به اندازه n – (k-1)/2 از ماتریس خروجی کاسته میشود. بسیارخب، واضح است که به همین اندازه باید سطر و ستون به ماتریس ورودی اضافه کنیم. مثلا فرمول n – (k-1)/2 برای فیلتر 3×3 میگوید که باید به ماتریس ورودی 2 سطر و ستون اضافه شود. یک سطر را بالای ماتریس ورودی قرار میدهیم و یکی را هم پایین ماتریس… یک ستون را سمت چپ ماتریس و دیگری را سمت راست… بهعنوان مثالی دیگر، اگر اندازه فیلتر 5×5 باشد، چهار سطر و ستون باید به ماتریس ورودی اضافه شود.
اندازه stride در لایه کانولوشن
اندازه stride را میتوان گام هم تعریف کرد. منظور از گام این است که فیلتر بعد از محاسبه در یک پنجره از ورودی، چند درایه یا خانه باید جلو برود تا دوباره محاسبات را انجام دهد. اگر اندازه گام را 1 درنظر بگیریم، یعنی فیلتر باید درایه به درایه در ورودی به سمت راست و پایین برود و اسکن را انجام دهد. یعنی، همان صحبتهایی که در بخش قبل (کانولوشن) داشتم. اما اگر مثلا stride عدد 2 درنظر گرفته شود، طبق شکل 21 مشاهده میکنید که دوتا دوتا میپرد.

معمولا stride در لایه های کانولوشنی عدد 1 درنظر گرفته میشود.
عملگر کانولوشن، یکی از مهمترین مولفههایی است که باعث میشود CNN نسبت به تغییرات مکانی مقاوم باشد. برای یک فیلتر با یک الگوی گربه، فرقی ندارد که گربه در کجای تصویر قرار دارد. درهرصورت آن گربه در تصویر را تشخیص میدهد. چون فیلتر کل تصویر را اسکن میکند و فارغ از موقعیت، گربه را تشخیص دهد.
لایه غیرخطی در شبکه عصبی کانولوشن (Activation Function)
مشابه با سایر شبکه های عصبی، شبکه عصبی کانولوشن هم از تابع تحریک یا activation function غیرخطی بعد از لایه کانولوشنی استفاده میکند. استفاده از تابع غیرخطی باعث ایجاد خاصیت غیرخطی در شبکه عصبی میشود که خیلی مهم است. بعضی از فریمورکها در همان تعریف لایه کانولوشنی، به شما این امکان را میدهند که نوع تابع غیرخطی را هم مشخص کنید. در بعضی از فریمورکها هم باید یک لایه جداگانه بسازید. تعریف تابع غیرخطی به صورت جدا از لایه کانولوشنی انعطاف پذیری بیشتری ایجاد میکند.
در بین تمام توابع غیرخطی، تابع ReLU بیشترین محبوبیت را دارد. البته، از خانواده ReLU اعضای دیگری مانند PReLU Leaky-ReLU و غیره وجود دارند. در شکل زیر، تعدادی از توابع غیرخطی را مشاهده میکنید. بهعنوان نمونه، تابع ReLU مقادیر کوچکتر از صفر (منفی) را صفر و مقادیر بزرگتر از صفر را بدون هیچگونه تغییری به خروجی میبرد.

محاسبات موجود در تابع ReLU ساده و صرفا یک مقایسه است. به همین خاطر محاسبات در بخش تابع غیرخطی با استفاده از ReLU نسبت به سایر توابع غیرخطی (مانند tanh sigmoid) با سرعت بیشتری انجام میشود. از طرفی فرآیند آموزش با ReLU نسبت به سایر توابع غیرخطی سریعتر است. چون، توابع غیرخطی tanh sigmoid در مقادیر خیلی بزرگ و کوچک به اشباع میرسند و این باعث میشود که گرادیان این توابع به سمت صفر میل کند. درنتیجه کل فرآیند بهینه سازی یا بهتر بگویم آموزش با سرعت پایینتری نسبت به ReLU انجام میشود. در شکل زیر، خروجی یک نمونه اعمال تابع تحریک ReLU به یک ماتریس ورودی را مشاهده میکنید.

لایه پولینگ در شبکه عصبی کانولوشن (Pooling Layer)
لایه پولینگ یکی دیگر از لایه های مهم در شبکه عصبی کانولوشن است. هدف لایه پولینگ کاهش اندازه مکانی فیچرمپ بدست آمده با استفاده از لایه کانولوشنی است. لایه پولینگ پارامتر قابل آموزش ندارد. صرفا یک نمونه برداری ساده و موثر انجام میدهد. پولینگ عملکردی شبیه کانولوشن دارد و یک پنجره روی تصویر حرکت میکند. رایجترین نمونه پولینگ max pooling و average pooling است. مطابق شکل 24 ماکس پولینگ شامل یک پنجره از پیش تعریف شده است (مثلا 3×3) که روی تصویر حرکت میکند (تصویر را اسکن میکند) و در هر پنجره مقدار ماکزیمم را انتخاب میکند و بقیه را دور میریزد. مشابه با لایه کانولوشنی، اندازه فیلتر، پدینگ و استراید در اینجا هم صدق میکند. در پولینگ، معمولا استراید 2 و اندازه فیلتر 3 درنظر گرفته میشود. برای اینکه سایز ویژگی به 1/2 کاهش پیدا کند.

در شکل زیر یک نمونه کامل از max pooling نشان داده شده است.

همچنین، در شکل زیر یک نمونه کامل از average pooling نشان داده شده است.

صبر کنید، صبر کنید! تا اینجا لایه کانولوشن، لایه غیرخطی و لایه پولینگ را آموختید. اما قبل از اینکه بخشهای بعدی را توضیح بدهم، میخواهم یک شبکه عصبی کانولوشن نصف و نیمه با همین ماژولها بسازم. برای ساخت یک شبکه کانولوشنی ساده لازم است نکاتی را مدنظر داشته باشید. بخش بعدی را دقیق بخوانید…
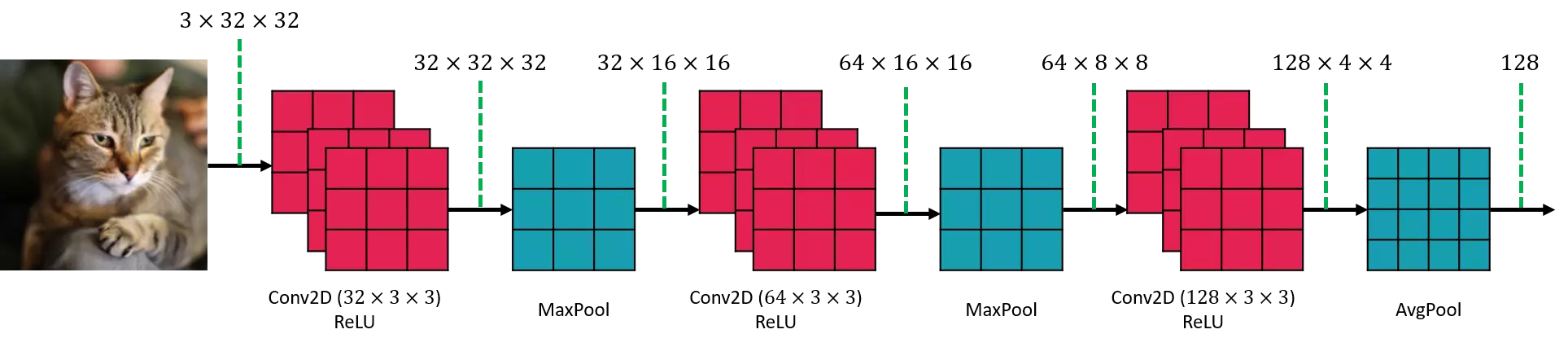
طراحی شبکه عصبی کانولوشن ساده
من در شکل 27 یک شبکه کانولوشن نصف و نیمه ساختم. به شکل نگاه کنید و نکتههای زیر را بخوانید:
- معمولا در شبکه عصبی کانولوشن، ابتدا لایه کانولوشنی قرار میگیرد. یعنی، قبل از پولینگ، تایع غیرخطی و غیره. ابتدا، یک لایه کانولوشنی روی تصویر با تعداد فیلتر کم اعمال میشود. لایه 1، با 32 فیلتر را در شکل زیر مشاهده میکنید. پدینگ و استراید طوری تنظیم شده که سایز فیچرمپ خروجی کم نشود. اندازه فیچرمپ خروجی برابر با 32×32×32 است.
- معمولا بعد از لایه کانولوشنی، یک تابع تحریک قرار داده میشود. طبیعی است، چون اگر یادتان باشد در نورون هم بعد از جمع وزندهی و جمع با بایاس، تابع تحریک اعمال میشد. طبق شکل زیر، یک تابع ReLU روی فیچرمپ اعمال میشود. کارش هم اینست که منفیها را صفر میکند، تمام!
- حالا میخواهم یک لایه پولینگ بعد از تابع تحریک قرار دهم. این پولینگ از نوع ماکس پولینگ است. اما استراید را 2 درنظرگرفتم که اندازه فیچرمپ خروجی نصف شود. پس اندازه فیچرمپ خروجی برابر با 16×16×32 خواهد شد.
- تا اینجا یک دور کانولوشنی، غیرخطی و پولینگ را به تصویر ورودی اعمال کردم. دوباره هرسه اینها را اعمال میکنم. تعداد فیلترهای لایه کانولوشنی دوم را 64 درنظر گرفتم. فیچرمپ خروجی ماکس پولینگ: 8×8×64
- در سومین مرحله، یک لایه کانولوشنی با 128 فیلتر درنظر گرفته شده و استراید هم 2 است. بعد از لایه کانولوشنی یک تابع تحریک گذاشتم. فیچرمپ خروجی تابع تحریک برابر با 4×4×128 است.
- در آخر یک لایه میانگین پولینگ با سایز 4×4 گذاشتهام. فیچرمپ خروجی این لایه برابر با 1×1×128 خواهد شد. یعنی، تصویر ورودی بعد از چندمرحله تبدیل به یک بردار به طول 128 شد. این بردار، بردار ویژگی تصویر ورودی است. این بردار شناسنامه یا اثر انگشت تصویر است. به چه دردی میخورد؟ دربخش بعدی خواهید دید…
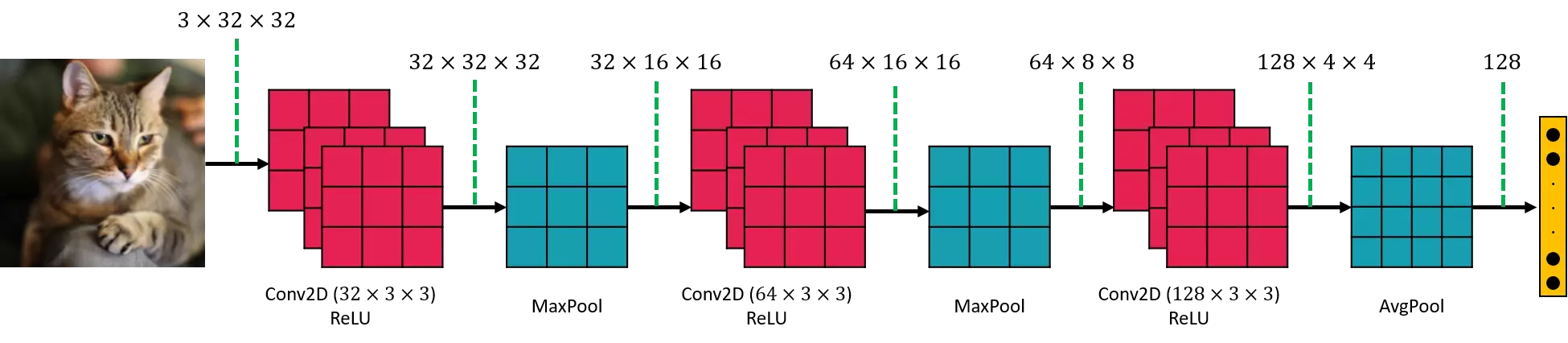
لایه فولی کانکتد در شبکه عصبی کانولوشن (Fully Connected Layer)
معمولا آخرین لایه های یک شبکه عصبی کانولوشن برای طبقه بندی را لایه های فولی کانکتد تشکیل میدهند. این لایه ها همان لایه هایی هستند که در شبکه عصبی MLP دیدهاید. برای آشنایی بیشتر این مقاله را بخوانید. یکی از کاربردهای اصلی لایه فولی کانکتد در شبکه کانولوشن، استفاده به عنوان طبقه بند یا کلاسیفایر (Classifier) است. یعنی مجموعه ویژگیهای استخراج شده با استفاده از لایه های کانولوشنی درنهایت تبدیل به یک بردار میشوند. درنهایت این بردار ویژگی به یک کلاسیفایر فولی کانکتد داده میشود تا کلاس درست را شناسایی کند. شکل 28 را با فولی کانکتد کامل کردم و میتوانید در شکل زیر مشاهده کنید. شکل زیر بلوک دیاگرام کامل یک شبکه عصبی کانولوشن ساده برای طبقه بندی است.
سوالات رایج درباره شبکه عصبی کانولوشن
انتظار دارم بعد از خواندن این پست بلندوبالا، یک عالمه سوال برایتان ایجاد شده باشد. من به تعدادی از سوالات رایج دانشجویان در ادامه جواب دادهام. سعی میکنم این بخش را بازهم با سوالات جدید تکمیل کنم. سوالاتی مثل:
- همیشه اول لایه کانولوشنی، تابع تحریک و بعد هم پولینگ؟ خیر، ممکن است تصمیم بگیریم چندلایه پشت هم کانولوشنی بگذاریم و بعد یک پولینگ قرار دهیم. برچه اساسی این کار انجام میشود؟ جواب این سوال سخت است، باید مقالههای مختلف در حوزه شبکه عصبی کانولوشن را بخوانید.
- چرا رفته رفته در شبکه جلوتر رفتیم، تعداد فیلترهای لایه کانولوشن بیشتر شد؟ سعی میکنیم رفته رفته ویژگیهای بیشتر و متنوعتری تولید کنیم.
- ماکس پولینگ و پولینگ میانگین را برچه اساسی انتخاب میکنیم؟ معمولا در لایههای میانی از ماکس پولینگ استفاده میشود و در پایان شبکه لایه پولینگ میانگین بهکار گرفته میشود.
- حالا این بردار ویژگی 128-تایی به چه دردی میخورد؟ همان ابتدا گفتم که من میخواهم یک شبکه عصبی کانولوشن برای طبقه بندی بسازم. این خروجی به من کمک میکند که من فرق بین گربه و سگ را شناسایی کنم. باید بردارهای ویژگی 128-تایی بهگونهای باشد که بردار ویژگی تمام تصاویر گربه شبیه هم باشد. همچنین، بردار ویژگی تصاویر سگ مشابه هم باشد، اما بردار ویژگی سگ و گربه باید از هم دور باشند. دو مجموعه بردار ویژگی داریم که گربهها نزدیک هم و سگها نیز نزدیک بههم است. پس، بردار ویژگی یک تصویر جدید تستی، به هرکدام از این دو بردار که بیشتر شبیه باشد، به همان کلاس متعلق هست.
دریافت PDF آموزش شبکه عصبی کانولوشن
برای شما هدیهای داریم. 😊 خیلی علاقهمند بودیم که PDF پست شبکه عصبی CNN را آماده کنیم. اتفاقا خیلی از دوستان هم پیام میدادند و PDF این آموزش را میخواستند. بالاخره بعد از مدتها، در تاریخ 17 آذر 1400 این PDF آماده شد. 😍 اگر بگوییم یک کتابچه شده، بیراه نگفتهایم! از طریق لینک زیر میتوانید دریافت کنید.
آموزش یادگیری عمیق رایگان
آموزش شبکه CNN یکی از سلسله پستهای آموزش یادگیری عمیق رایگان است. در جدول زیر، فهرست مطالب دوره آموزش یادگیری عمیق رایگان هوسم را آوردهایم.
جلسه 01: نورون مصنوعی
نورون مصنوعی
جلسه 02: یادگیری نورون مصنوعی
یادگیری نورون مصنوعی
جلسه 03: شبکه عصبی MLP
شبکه عصبی MLP
جلسه 04: پروژه دستهبندی MLP با تنسورفلو
دسته بندی با mlp و تنسورفلو
جلسه 05: پروژه رگرسیون MLP با تنسورفلو
رگرسیون با mlp و تنسورفلو
جلسه 06: شبکه عصبی کانولوشن (CNN)
شبکه عصبی کانولوشن
جلسه 07: شبکه عصبی بازگشتی (RNN)
شبکه عصبی بازگشتی
جلسه 08: شبکه عصبی GAN
شبکه عصبی GAN
جلسه 09: شبکه عصبی LSTM
شبکه عصبی LSTM
واقعا به پایان رسیدم؟!
جواب کوتاه اینکه، نه! 😅 اما، خداقوت، گام بزرگی برداشتید. از ابتدا تا انتهای یک شبکه CNN را خدمت شما توضیح دادم. امیدوارم، با این شبکه محبوب ارتباط برقرار کرده باشید. مفاهیم و لایههای دیگری نیز در شبکه عصبی کانولوشن وجود دارد. مثلا، باید درباره Batch Normalization, Dropout, Data Augmentation, Receptive Field هم توضیح بدهم. اما فعلا تا همین اندازه کافی است و بقیه بماند در پستی جداگانه… لطفا فیدبک بدهید، این آموزش چطور بود؟ در کامنت درباره این پست با ما صحبت کنید. هوسم را هم فراموش نکنید و لطفا به دوستانتان هم معرفی کنید…
مطالب زیر را حتما مطالعه کنید
شبکه ترنسفورمر

روش اعتبارسنجی متقابل یا cross validation چیست

مقایسه تنسورفلو و پایتورچ

شبکه عصبی GRU

یادگیری عمیق چیست

آموزش matplotlib در پایتون
245 دیدگاه
به گفتگوی ما بپیوندید و دیدگاه خود را با ما در میان بگذارید.
ممنونم منو نجات دادین! خیلی خوب توضیح دادین فقط یجا سوالی برام پیش اومد برای فرمولی که گفتین چجوری اندازه padding را حساب کنیم یجا گفتین m = n – (k-1) و جای دیگر بر 2 تقسیم کردین, میشه بگین کدوم فرمول برای حساب کردن اندازه پدینگ هست و اینکه n که گفتین برابر با اندازه ماتریس فیلتر هست یعنی اگر ماتریس ما برابر با 3 در 3 باشد n هم برابر با 3 میشود یا برابر با 9؟ ممنونم
سلام
متغیرهای n و k بهترتیب برابر با سایز ورودی و فیلتر هستن. حالا یک مثال ببینیم؛ اگر ورودی 100×100 و فیلتر 5×5 داشته باشیم، خروجی میشه: m=n-(k-1)=100-(5-1)=96
یعنی، سایز خروجی 96×96 هست. چون ورودی و فیلتر مربعی هستن (سطر و ستون برابر)، به همین خاطر ما یک عدد 100 و 5 رو برای محاسبه سایز خروجی استفاده کردیم. اما، اگر سایزها غیرمربعی باشه، اونوقت برای سطر و ستون باید بهصورت جداگانه حساب و کتاب رو انجام بدیم.
ممنون ازتون. هیچ جا به این خوبی قابل فهم توضیح نداده بود.
از چه بابت هرچه اعداد درایه های فیلتر به درایه های پنجره ورودی نزدیکتر باشه، خروجی (مجموع حاصل ضرب درایه های متناظر) بیشتر میشه؟
مثلا اگر تمام درایه های فیلتر 2 باشن و تمام درایه های ماتریس زیرش هم 2 باشن (100درصد تطابق) خروجی یه عددی میشه
حالا اگر درایه های ماتریس پشتی 3 باشن، با اینکه تشابه کمتر شده ولی خروجی بیشتر میشه
من این قسمت رو متوجه نشدم.
سلام
مساله رو ساده کنیم؛ سه بردار در داریم که میتونیم در فضای دوبعدی رسم کنیم. بردار [1,1]=v با بردار [1,1]=w همراستا هست. طبیعتا، بردار [1,1]=v با بردار [2,2]=u هم همراستا هست. اعداد 2 صرفا مقیاس هستند: [1,1]2=u
انقدر آسون و سلیس مطالبو میگید آدم کیف میکنه ، ممنونم ازتون، خسته نباشید
سلام ، از آموزش خوبتون سپاسگذارم ، مثل همه آموزشهاتون گام به گام و روشن پیش رفتید و جنبه گنگی باغی نذاشتید . امیدوارم در تمام مراحل موفق و سالم باشید .
با سلام و خدا قوت!!! دمت گرم. ۲ ساله دارم resource میبینم کد میزنم ولی نفهمیده بودم تکنیکال داره چطوری کار میکنه
من صمیمانه ازتون تشکر میکنم بابت این شیوایی کلام و آموزش کاملتون… به جرات تو منابع فارسی کم نظیر هست مطابتون … پاینده باشید
سلام و خداقوت به تیم هوسم
برای پایان نامه ام مجبور بودم از روش های یادگیری کلاسیک مثل فارست و بردار ماشین (و زبان برنامه نویسی متلب) سوییچ بشم به یادگیری عمیق.بخاطر سردرگمی در فهم مطالب یه فوبیای وحشت ناکی مانع از این میشد که کتاب های این حوزه یا فیلم های یوتیوب رو ببینم.اما بالاخره بعد چند ماه با خوندم مطالب شیوا با بیان ساده و روان سایت شما اون فوبیا شکسته شده و علاقه مند به مطالعه در این حوزه شدم.خدا خیر دنیا و اخرت نصیب همه اعضای تیم هوسم کنه.
پایدار باشید.
سلام
بعد از گذراندن یک دوره پردازش تصویر مطالب این بخش را مطالعه کردم و با توجه به اون مفاهیم برام بسیار روشن شد. باتشکر
nice and completer
سلام خیلی ممنون بابت زحمتی که کشیدید واقعا عالی و کامل بود.
فوق العاده روان و قابل فهم.
آرزو میکنم که در اجرای این طرح خداپسندانه موفقیت روزافزون نصیب حضرتعالی و تیم قوی شما ،شود.
پیروز باشید
باسلام و درود.بسیارعالی بود.ممنونم بابت از آموزش های مفیدتون.متشکرم.موفق باشید.🙏🙏🙏🙏👏👏👏
باسلام و درود.بسیارعالی بود.متشکرم.🙏🙏🙏🙏👏👏👏
عااالی بود واقعا ممنون. بهترین ها براتون رقم بخوره.
سلام
خیلی عالی و قابل فهم
سپاسگزارم.
سلام
از مطالب خوبتون ممنونم. لینک دانلود pdf آموزشی که ایمیل شد، غیر فعال است. از چه طریق می توانم دریافت کنم؟
سلام🌹
مشکل برطرف شد دوست عزیز😊
ممنون که اطلاع دادید🙏
سلام
با اختلاف بسیار فاحش در زمینه CNN بهترین آموزشی بود که تا الان دیدم.
واقعا عالی بود.
سپاس از این همه تلاش
در پناه خدا سلامت و پاینده باشید
بسیار سایت عالی و مفیدی دارید. ممنون از زحماتتون.
سلام
بسیار عالی توضیح دادید. لطفا در خصوص اجرای آن هم در کد نویسی راهنمایی کنید.
درود برر شرفتون
من اولین بار بودهمچین توضیحات کاملی ب فارسی دیده بودم . خدا سامتی بده بهتون.
فقط سوالی ک دارم اینه قضیه ی input_shaap ک تو لایه کانوولژن میگیره چیه و چطور بایدد واردش کنیم
سلام ممنون عالی بودید
انقدر جذاب، دقیق، با حوصله، واضح، روان، مدون، کامل، با جزییات و … توضیح میدید. اون مطالبی هم که بلدم را دوباره تو سایتتون میخونم.
مراقب خوبیهاتون باشید.
سپاس
ممنون بابت پیامتون🌹
سلام واقعا عالی است
هنوز دارم بقیه را مطالعه میکنم
برای ترجمه یک مقاله در این رابطه به مشکل برخوردم که
مطالب سایت شما خیلی راهنماییم کرد.
تشکر می کنم و سپاسگزارم
اقا خیلی عالی بود استفاده کردیم.
سپاس از شما
تا حالا نظر برای هیچ مطلبی نداشته بودم اما به خاطر استفاده از مطالب و نحوه ی بیان مباحث به شکلی که قابل درک بود واجب شد نظر بدم واقعا ممنون از کمک شما به پیشرفت دانشجو ها و آموزش عالیتون
سلام سپاس از توضیحاتتون لطفا راجب capsul network که ادامه شبکه های کانالوشنی هست هم مطلب بگذارید .
سلام درود بر شما .عالی بود .
سلام ممنون توضیح تقریبا کامل و شفافی بود البته عالی
سلام خدا قوت
ممنونم از مطالب خوب و عالیتون
من دانشجوی ارشد نرم افزار هستم و دارم پایان نامه ام رو مینویسم میخام با اجازه شما قسمتی از مطالب شما در پایان نامه خودم بیارم منتها باید رفرنس به مقاله انگلیسی بدم.ممنون میشم رفرنس های انگلیسی مطالبتون رو هم بزارید
با تشکر فراوان
سلام من یک سری عدد در اکسل دارم میتونم با سیگنال یا ترند نشانش بدم برای تبدیل این اعداد به تصویر )کاری که در cnn ( انجام میشه راهنماییم کنید آیا این کار انجام بدم اصلا با نه لازم نیست چگونه اون سیگنالها را بفرستم به شبکه cnn برای کلاسبندی
سوال : اصلا کلاس بندی مثلا ۶ کلاسه لازمه از cnn استفاده کرد؟
سلام
خیلی ساده و بدون حاشیه مطالب رو بیان کردید. خیلی از ابهاماتم برطرف شد.
ممنون
سلام خسته نباشید واقعا.
توضیحات عالی، بدون نقص، جامع و قابل فهم بود.
سلام، بسیار روان و شیوا و کامل بود.ممنون
سلام
کامل مطالعه کردم و برام جالب بود تنها سایتی هستید که مطالب رو کامل و دقیق بدون هیچ گونه ایراد نوشته بودید.
خدا خیرتون بده.
ممنونم از سایت مفیدتون. واقعا بیان قابل فهمی دارید
واقعا عالی بود لذت بردم. کامل و با دقت خوندم
اگه میشد کاربرد انواع ابرپاارمترهای مختلف شبکه های عصبی رو هم توضیح بدین عالی میشه واقعا.
ضمنا تا به حال به شباهت شتر و زرافه فکر نکرده بودم، ولی بعد از خوندن این متن دنبال تفاوت فیس شتر و زرافه بودم :)))
😅
سلام وقت بخیر و خسته نباشید خدمت تیم هوسم عالیه مطالبتون اگر امکانش هست واسه هربخش یه مثال متلبی و پایتون بزنید خیلی ممنون میشیم
با سلام و خسته نباشید
واقعااا خیلییی عالیه وو ممنونم از سایت خوبتون که در اختیار عام قرار گذاشتین دمتون گرم 🧡🌹🌷
سلام وقت خوش با تشکر از توضیحات جامع و کاملتون
یک سوال دارم قاعدتا میدونیم با افزایش تعداد لایهها، تعداد فیلترها هم افزایش پیدا میکنه و به عنوان مثال در لایه اول، فیلترها الگوهایی مانند لبه ها، گوشه ها، نقطه ها و غیره را به تصویر میکشند و سپس لایههای بعدی این الگوها را برای ایجاد الگوهای بزرگتر ترکیب میکنند (مانند ترکیب لبه ها برای ایجاد مربع، دایره و …).
حالا هرچه لایه به لایه جلو میرویم، الگوها پیچیدهتر میشوند و تعداد فیلترها هم بیشتر میشوند. لطفا دلیل افزایش تعداد فیلتر همزمان با افزایش لایه ها را توجیه کنید و بفرمایید پرا استخراج فیچرمپ های سطح بالاتر تعداد فیلتر بیشتری نیاز دارد یا اگر منبعی در این خصوص سراغ دارید بفرمایید لطفا.
سپاس
سلام
وقتی ورودی یک ویژگی سطح پایین هست، ما هم تعداد فیلترها رو کم میذاریم. اگه تعداد فیلترها رو زیاد کنیم، ممکنه ویژگی تکراری در خروجی زیاد بشه. فرض کنیم توی یک زمین دنبال گنج هستیم و یک ورودی سطح پایین معادل یک زمین خشک و خالی هست. یجورایی معادل “گشتم نبود، نگرد نیست”.
وقتی ورودی یک ویژگی سطح بالا هست، میگیم اوه اوه اینجا پر گنجه! باید کل زمین رو دقیق بررسی کنیم! اینجاست که بیشتر کردن فیلترها منطقیه.
خدا قوت در یک کلام عالی هستید
واقعا دمتون گرررم…خیلی خوبید.ممنونم بابت آموزشهای خوبتون
واقعا از این مطالب مفیدی که قرار دادین سپاس گزارم
از معدود منابعی هست که به زبان فارسی هست و دنبال کردنش لذت بخش هست
قطعا سایت شمارو به دوستانی که علاقه مند به این حوزه هستن معرفی خواهم کرد
سلام
بسیار عالی
ممنون از زحمات شما
سلام واقعا از توضيحاتتون ممنونم،كاش براي بچه هاي مخابراتم مطلب بزاريد. سپاس بيكران
سلام. من دانشجوی هوش مصنوعی شریف هستم و به جرئت میتونم بگم که هیچ آموزش یا محتوایی بهتر از این مطلب، نمیتونه CNN رو آموزش بده. واقعا ازتون متشکرم. بسیار بسیار عالی بود.
سلام،
شیوه بیان و آموزش بسیار عالی بود.
من فقط یک سوال داشتم:
در شکل 27، چرا تنسور لایه های کانولوشن 3 بعدی شد؟ نباید 4 بعدی باشد؟ مثلا در دومین مرحله، ابعاد فیچرمپ ورودی 32 در 16 در 16 است، یعنی 32 تصویر 16 در 16. حال چگونه 64 فیلتر 3 در 3 با آن کانوالو شد؟ آیا 32 تصویر را merge کردید؟ چگونه؟
سلام
دقیقا باید چهاربعدی باشه. مثلا برای همون لایه کانولوشنی اول، باید کرنل کانولوشنی 3*3*3*32 باشه. یعنی 32 فیلتر به ابعاد 3*3*3…
اشتباه از ماست. ضمن تشکر از شما که ریزبینانه آموزش رو دنبال کردید، الان اعصابمون خورده که چرا حواسمون نبوده! 🥺
کارتون با کیفیت و درسته،
ممنون از پاسخ دهی
واقعا مثل همه ی بخش های دیگه سایتتون این آموزش هم فوق العاده بود. تبریک میگم بهتون بابت این قدرت بیان عالی. ممنونم.
یک سوال دیگه هم برام پیش اومد
برای انجام sentiment analysis با استفاده از cnn ، کمکی که cnn به ما میکنه صرفا بحث استخراج ویژگی هست ؟ و در آخر برای مشخص کردن مثبت یا منفی بودن جمله باید سراغ یک classifier برم ؟
سلام
مدت ها بود برای کار روی ترکیب BI-LSTM و CNN به دلیل کم اطلاعی در برخی جزییات دچار مشکل بودم .
خیلی مطالب سایتتون مفید بود . واقعا ممنونم .
در مورد CNN اگر ورودی متن داشته باشیم برای SENTIMENT ANALYSIS ، از CNN دو بعدی باید استفاده کنم درسته ؟
سلام
ما درمورد کار شما اطلاعاتی نداریم، نمیتونیم نظر بدیم.
موفق باشید 🌹🙏
تازه با ساییتون آشنا شدم.خیلی عالی و قشنگ توضیح دادید.واقعا ممنون
پس به هوسم خوش اومدید. 😊🌹🙏
عالی بود واقعا. لذت بردم از مطالعه متن شما
بسیار ممنون 🌹🙏
سلام و خسته نباشید عالیه سایتتون. خیلی روان و قشنگ توضیح میدید. فکر نمیکنم سایتی باشه که مثل شما خیلی مسلط توضیح بده.
فقط راجع به ماتریس کرنل یا فیلتر، من متوجه نشدم چطور باید اعداد داخل فیلتر رو انتخاب کنیم تا ویژگی های مختلف استخراج بشن
سلام
سپاس🌹
در بخش سوم اشاره شده:
“در نورون پارامترها متغیر بودند و از طریق فرآیند آموزش بدست میآمدند. اینجا هم اعداد موجود در فیلتر از طریق فرآیند آموزش بهدست میآیند.”
اینجا کلیک کنید
اگه این توضیحات کافی نبود، جلسه دوم رو مطالعه کنید:
لینک جلسه دوم
با درود و ستایش مجدد
امکانش هست در مورد این مباحث هم توضیح مختصری بدهید.
Batch Normalization, Dropout, Data Augmentation, Receptive Field
با سپاس فراوان
سلام
بله، این موارد رو در برنامه داریم.
ممنون بابت پیشنهاد 🌹🙏
بادرود و ستایش
خدا قوت واقعا پست فوق العاده ای بود. با سپاس از زحمات شما
ممنون اشکان عزیز 🌹🙏
سلام واقعا عالی بود ممنون.
ممنون 🌹🙏
سلام
تشکر از توضیحات بسیار روان خیلییی ممنون
ممنون از شما بابت کامنت 🌹🙏
سلام من برای دریافت pdf ایمیل وارد کردم ولی pdf دریافت نشد و پوشه spam هم چک کردم چیزی نمی اید
سلام رضا عزیز،
گاهی اوقات ممکن هست مشکل از سمت ما باشه و ایمیل خودکار با تاخیر ارسال شه یا اصلا ارسال نشه.
البته، گاهی اوقات دوستان خطای تایپی در نوشتن ایمیل دارن.
ما به ایمیلی که وارد کردید، بهصورت دستی pdf رو ارسال میکنیم.
ممنون 🌹🙏
سلام بسیار عالی بود، خدا قوت.
سلام
سپاس 🌹🙏
به جرعت میتونم بهترین آموزش فارسیای بود که دیدم
بسیار سپاسگزارم
ممنون محمد عزیز 😊🌹🙏
سلام
خیلی عالی و دقیق توضیح دادین
ممنون از شما
فقط لذت بردم .ممنونم
ممنون 🌹🙏
عالی. آرزوی موفقیت برای تیمتون
سپاس 🌹🙏
سلام وقت بخیر
من برای پایان نامه باید از شبکه عصبی کانولوشنی برای تشخیص و شناسایی حمله به شبکه استفاده کنم ولی نمیدونم این شبکه عصبی چطور میتونه به کار گرفته بشه در این مورد با توجه به اینکه توضیحات تماما در مورد شناسایی و استفاده از پردازش تصویر است میتونید راهنمایی کنید منو؟
کجا و در چه برنامه ای باید پیاده سازی کرد؟
سلام
شبکه کانولوشنی میتونه روی دادههای تصویر، صوت، متن و غیره هم اعمال بشه. اما قبل از هرچیز باید تئوری و کدنویسی شبکه عصبی و بهخصوص شبکه عصبی کانولوشن رو خوب یاد بگیرید. اصلا مهم نیست که براساس تصویر باشه، مهم این هست که کامل به این شبکه مسلط بشید. برای شما آموزش خوب دیدن ضروری هست. به نظر ما درنگ نکنید و یک دوره یادگیری عمیق خوب بگذرونید.
پ.ن: پیشنهاد ما برای تهیه دوره یادگیری عمیق، تبلیغاتی نیست. بلکه، باتوجه به شرایطتون، گذروندن یک دوره خوب رو برای شما ضروری میدونیم. حالا خودتون تحقیق کنید یا از هوسم یا از هر موسسه دیگهای که بهتر هست، آموزش ببینید.
موفق باشید
عرض سلام و وقت بخیر
برای شکل ۱۷، مگر نباید ابعاد خروجی کمتر از ۱۰۰ شود؟به دلیلی تاثیر کرنل روی تصویر ورودی؟ مثلا اگر پدینگ نداشته باشیم و استراید ۱ باشد، باید ۹۶*۹۶ شود. ایا برداشت من اشتباه است؟
سلام
اگه پدینگ نداشته باشیم، خروجی 96*96 میشه. تو این تصویر ما دغدغه ابعاد سطر و ستون خروجی رو نداشتیم، بلکه میخواستیم بگیم که اگه ورودی چندکاناله باشه، فیلتر و خروجی شامل چند کانال میشه؟ میشه فرض کرد که پدینگ داریم تا اون 100*100 درست باشه.
عالی عالی عالی
بسیار قابل فهم و ساده توضیح داده شده
حرفی برای گفتن باقی نمیمونه
ممنون دانشجوی پرمشغله 😊🙏🌹
سلام ممنون از مطلب خوبتان. متاسفانه الان فرصت مطالعه کامل رو ندارم، به این خاطر مطلب رو بوکمارک کردم تا بهزودی کامل مطالعه کنم. با بررسی اجمالی که کردم بسیار عالی مطالب پوشش داده شده و زحمت زیادی براش کشیدید. مرسی.
سلام
خدا رو شکر فیدبکهای مثبتی برای این آموزش دریافت کردیم. انشالله این آموزش برای شما هم مفید باشه.
ممنون 🌹🙏
با سلام
درود بر شما
مطالب عالی بود.
سپاس 🌹🙏
سلام درود بر شما
بسیار عالی و مفید بود.
خدا خیرتون بده
ممنون 🌹🙏
خیلی خیلی عالی و قابل فهم و با چه عشقی این تصاویر متحرک را ساختید دم شما گرم لطفا روی سئو سایت کار کنید چون من تصادفی سایتتون را پیدا کردم و توی نتایج اول سرچ گوگل نیستید ممنون از شما بابت انتقال دانشتون
سلام
خیلی خیلی خوشحال میشیم وقتی چنین پیامهایی رو میبینیم. بابت پیشنهادی هم که برای بهبود سئو دادید، بسیار بسیار ممنون. بیشتر تلاش میکنیم.
موفق باشید 🌹🙏
بسیار عالی.باسپاس
ممنون از شما بابت کامنت 🌹🙏
خیلی عالی بود. بخصوص تصاویر
پایدار باشین 🙂
ممنون 🌹🙏
سلام و خدا قوت
خیییلی عالی بود ، مطالب شیوا و قابل فهمی ک ب اشتراک گذاشتین نشان دهنده دانش عمیق شماست
خوشحالم ک برای چنین مطالبی سایت فارسی خوبی مث اینجا هست.
انشالله کارتون ادامه دار باشه. بازم ممنون خیلی خیلی ممنون. موفق باشید
سلام
ممنون. پیامتون به ما انرژی مثبت داد.
باور ما این هست که میتونیم در داخل کشور، سایتهای آموزشی علمی در سطح بالا داشته باشیم. انشالله بتونیم در این مسیر ثابت قدم باشیم و مدام پیشرفت کنیم. امیدواریم، مخاطبان عزیز هم از ما حمایت کنن و با تهیه قانونی دورههای هوسم به ما کمک کنن تا بتونیم گامهای بزرگتری برداریم.
موفق باشید 🌹🙏
با تشکر از مطالب بسیار مفیدتون
در فرمول محاسبه سایز ماتریس خروجی پس از اعمال فیلتر، به نظر تقسیم بر ۲ نباید بشه
m=5-(3-1)=3
سلام. ممنون بابت اطلاعات مفید و ارزشمندتون 🙂
سوال: آیا میشه شبکه کانولوشن رو برای دیتاست های جدولی که فقط شامل سطر (نمونه) و ستون (ویژگی) هستن، استفاده کرد؟
داده ها رو به همین شکل (مثلاً داده هایی با پسوند csv) میشه بعنوان ورودی به شبکه بدیم و عملیات بر روی اونها انجام بشه؟
سلام
اگر بخوایید دادهها رو به صورت یک ماتریس دوبعدی ببینید و بعد هم شبکه کانولوشن دوبعدی اعمال کنید، جواب خیر هست. اما میتونید شبکه کانولوشن یک بعدی طراحی کنید تا فیلترها روی هر سطر یا نمونه، ویژگیها رو باهم ترکیب کنن.
این سوال من هم بود. چیزی که متوجه شدم برای مسایل تخمین انگار باید اون سیگنال یا توالی ورودی رو از یه راهی به یه ماتریس دو بعدی(حدااقل تبدیل کرد) یا از طریق استخراج ویژگی قبل از اعمال به شبکه ویژگی های سیگنال رو به صورت تصویر به شبکه داد.نمی دونم تا چه حد این دریافت من از منابع صحیح هست؟ از تیم هوسم خواهش میکنم که اشتباهاتی که در فهم این مسئله داشتم رو اصلاح بفرمایند.
با تشکر
در این پست، رایجترین شکل شبکه عصبی کانولوشن (کانولوشن دوبعدی) توضیح داده شد. اما این تنها ساختار شبکه عصبی کانولوشن نیست و شبکه عصبی کانولوشن یکبعدی و سهبعدی هم داریم. از شبکه کانولوشن یکبعدی در مسائلی با سیگنالهای یک بعدی مثل صوت و سری زمانی استفاده میشه. شبکه CNN سهبعدی هم در مسائل مبتنی بر ویدئو کاربرد داره.
بنابراین، بسته به مساله و داده باید تصمیم بگیرید که چه شبکهای با چه ساختاری مناسب هست. مثلا برای دیتاست جدولی یا تبولار معمولا از شبکه MLP استفاده میشه. البته اخیرا ترنسفورمرها هم در دیتاست جدولی به کار برده میشه.
در رابطه با شبکه عصبی Dense net در سایت مطالبی دارید آیا؟ من متاسفانه پیدا نکردم.
در وبلاگ برای شبکه عصبی DenseNet مطلبی نداریم. اما در دو دوره آموزش یادگیری عمیق و دوره بینایی کامپیوتر حرفهای درباره این شبکه صحبت شده.
بسیار بسیار مفید سپاس فراوان
ممنون 🌹🙏
باسلام
راستش دلم نیومد با خوندن این مطلب عالی و بی نظیر کامنت نزارم و ابراز علاقه به مطالب سایت شما نکنم
امیدوارم پیروز و موفق باشیدهمیشه که اینقدر با حوصله و سخاوتمندانه و مسلط توضیح دادید
قطعا نتیجه این عمل خیری که انجام دادید رو تو زندگی شخصیتون خواهید دید
با سپاس فراوان
سلام
کامنت شما به ما یک عالمه انرژی داد و از ته دل خوشحال شدیم.
با آرزوی موفقیت 🌹🙏
یعنی معرکه بود. حتما سایتتون رو به افرادی که توی این حوزه از من سوال کنند معرفی میکنم. مقالاتتون خیلی با کیفیت هست و برعکس بسیاری از سایت ها که فقط مسائل رو پیچوندن، سایت شما خیلی واضح و خوب همه چیز رو بیان کرده.
سلام
مایه افتخاره که به دیگران ما رو معرفی میکنید.
بسیار ممنون 🌹🙏
لطفا فرمول سایز خروجی کانولوشن را با مثال و جاگذاری توضیح دهید چون برای مثالی که داخل متن بود بنظر فرمول مورد نظر برقرار نبود.
سلام
لطفا دوباره به فرمول نگاه کنید و اعداد رو جایگذاری کنید. ما یک پرانتز اضافه کردیم که تقدم و تاخرها رعایت بشه.
سلام ممنون از این پست ارزشمند.
مشکل به خاطر ابهام در جمله هست که نوشته شده:
“ماتریس ورودی و فیلتر مربعی باشند و سایز آنها بهترتیب برابر با k و n باشد.”
وقتی نوشته شده به ترتیب، خواننده این برداشت را میکنه:
ماتریس ورودی: k
فیلتر: n
عالی بود. ممنون
ممنون از شما بابت کامنت 🌹🙏
خیلی عالی بود خدا قوت
سلاااااام
عااااااالی و بسیار مفید بود
خدا قوت🤩🤩
ارادت 🌹🙏
سلام
وقت بخیر
چرا در بعضی از شبکه ها از دو لایه کاملا متصل استفاده میکنند؟
سلام
در شبکههایی مثل VGG از چند لایه فولی کانکتد استفاده شده، اما بعدا اکثر شبکهها فقط با یک لایه فولی کانکتد طراحی شدن. دلیلش این بود که میخواستن اون ویژگی استخراج شده از تصویر رو با چند بار نگاشت به ویژگیهای غنیتر تبدیل کنن. همچنین، در اونجا ابعاد ویژگیها رو مثلا کاهش بدن و بعد اون ویژگی رو به کلاسیفایر بدن.
سوالم اینکه مثلا چرا لایه کاملا متصل اول رو 152 تا نرون استفاده شده و لایه کاملا متصل بعدی رو 64 تا نرون استفاده کردند. دلیلش چیه؟
سلام
ممنون از مطالب مفیدتون سوالی داشتم . منظور از شبکه عصبی کانولوشن یک بعدی چیست؟ ورودی شبکه وفیلترها در این شبکه چه تفاوتی با شبکه کانولوشن دو و سه بعدی دارند؟
سلام
یعنی کرنلهای کانولوشنی یک بعدی هستن. در حالت دوبعدی کرنلها شامل سطر و ستون بودن. ورودی هم دیگه تصویر نیست، مثلا میتونه صوت باشه.
میشه درباره Batch Normalization, Dropout, Data Augmentation, Receptive Field هم مطلب بذارین ؟ واقعا خوب توضیح میدین .. جای دیگه همینارو کلی پیچونده توضیح داده
سلام GPU چطور روی پایتون نصب میشه و اصولن چی هست ؟ممنون اگه راهنمایی کنید .
یک نمونه سورس کانولوشنی دراین قسمت با توضیحاتش لطفا بذارین
سلام
GPU روی پایتون نصب نمیشه. پایتون بهصورت مستقل از GPU و CPU نصب میشه. فریمورک پایتورچ و تنسورفلو رو میشه مبتنی بر GPU یا CPU نصب کرد. برای استفاده از GPU در پایتورچ و تنسورفلو هم باید CUDA و CUDNN نصب کنید.
درمورد سوال بعدیتون که فرمودید GPU اصولا چی هست؟ توضیح در چند خط کافی نیست و بهتر هست جستجو و مطالعه کنید. بهصورت خلاصه، GPU به عنوان یک پردازنده با داشتن هستههای کودا قدرت بیشتری در محاسبات ریاضی نسبت به CPU به ما میده. ما هم در شبکه عصبی حجم زیادی محاسبات ریاضی داریم. پس به همین خاطر از GPU استفاده میکنیم.
برای درک عمقیتر مطالب و همچنین آموزش کدنویسی، به شما دوره آموزش یادگیری عمیق رو پیشنهاد میکنیم.
ممنون از آموزش بسیار خوبتون
سپاس
سلام وقتتون بخیر
واقعا عالی بود و امیدوارم همیشه موفق باشید در هر زمینه ای…
یه سوال داشتم خدممتون…من حدود 50 فیچر ورودی(تصویر) دارم که هر کدوم ۶۰۰×600 سایزشونه که از انها حدود ۷۰۰۰۰نمونه اموزشی رو برای طبقه بندی ده کلاس استفاده کردم…این کار رو با mlp و به کمک gpu انجام دادم و با زمان کمتر از ۱ساعت با صحت 90درصد استخراج کرده…
میخواستم بدونم این کار با cnn امکانپذیره که این تعداد ورودی رو بپذیره؟ و ایا از لحاظ زمانی و سخت افزاری efficient هست؟
استراید آخرین لایه چقدر بود که خروجی شد یک بردار به طول 128 ؟
معمولا در آخرین لایه، از یک پولینگ میانگین استفاده میکنیم. حالا سایز کرنل، پدینگ و استراید رو هم طوری تنظیم میکنیم که خروجی تبدیل به یک بردار بشه. مثلا، ورودی پولینگ 4×4×128 بود که با یک پولینگ با کرنل سایز 4 و بدون پدینگ، خروجی میشه 1×1×128 که در واقع یک بردار به طول 128 هست.
سلام و خسته نباشید به شما و تیم خوبتون ..
لازم دونستم تا اینجای آموزش که با شما پیش اومدم یه خسته نباشید و خدا قوت بهتون بگم ..
واقعا عالی بود… خیلی دنبال یه منبع بودم که بتونم باهاش ارتباط برقرار کنم و این مفاهیم رو یاد بگیرم .. میتونم به جرئت بگم از بهترین ها هستین ..
اگه ممکن هست در مورد این شبکه عصبی مطلب بیشتری بذارین .. کد نویسیش رو هم اگه آموزش بدین که عاالیییییییییی میشه ..
سلام
خوشحالیم که آموزشها برای شما مفید بوده.
ممنون 🌹🙏
سلام عالی و بی نظیر هستید فقط کی سراغ کد میریم؟
سلام
فعلا برنامهای برای کد نداریم. البته قبلا آموزش pytorch رایگان رو نوشتیم. اگر هم به دنبال یک آموزش جامع هستید، به دوره آموزش یادگیری عمیق یا دوره آموزش پایتورچ نگاهی بندازید.
ممنون 🌹🙏
عالی عالی عالی متشکرم
سپاس 🌹🙏
سلام. واقعا عالی و شیوا بود. بی صبرانه منتظر ادامه دادن این پست و بقیه آموزش هاتون هستیم خصوصا در زمینه شبکه های عصبی
سپاس 🌹🙏
تلاش میکنیم آموزشهای باکیفیتتری رو آماده کنیم.
ایا این جمله درست هست؟ کانال ها و feature maps ها یکسان هستند. سپاس
سلام
خیر. دو مفهوم متفاوت هست.
به ویژگیهای خروجی یک لایه کانولوشنی فیچرمپ گفته میشه. فیچرمپها معمولا تنسورهای سهبعدی هستن. مثلا بهصورت 14×14×512. 14×14 معادل با سطر و ستون هست و عدد 512 معادل با تعداد کانالهاست. پس کانال یکی از بعدهای فیچرمپ هست.
سلام خسته نباشید
منظور از هسته چی هست؟ مثلا جمله پنجره فیلتر اولین لایه کانولوشن به صورت 256 × 4 با 50 هسته تنظیم شده است. منظور از 50 هسته چی هست؟ در کل اگه میشه این جمله به صورت ساده توضیح دهید. ممنون
سلام
هسته یعنی فیلتر یا کرنل.
معمولا در هر لایه کانولوشنی، تعداد زیادی هسته یا فیلتر برای استخراج ویژگیهای متنوع درنظر گرفته میشه. مثلا شما 50 فیلتر یا هسته برای یک لایه کانولوشنی درنظر گرفتید.
سلام. در مورد GCN هنوز مطلبی منتظر نکردید؟
سلام
خیر
موفق باشید 🌹🙏
خیلی ممنون از مطالب خوبتون
یه سوال داشتم
توی پیاده سازی شبکه CNN وقتی لایه MaxPooling را میخوام به مدلم بدم باید یه آرگومان به نام pool_size تعیین کنم. این pool_size چیه دقیقا؟
خیلی ممنون
سلام
احتمالا به سایز کرنل در پولینگ اشاره میکنه. مثلا میتونه 3×3 باشه. درمورد سایز کرنل پولینگ در همین آموزش شبکه عصبی کانولوشن توضیح دادیم.
سلام و سپاس بیکران بابت مطالب بسیار مفیدی که خیلی واضح و روان بیان کردید.
سلام
سپاس 🌹🙏
با سلام …من در حال آموزش طی یک دوره حضوری در یکی از مراکز تاپ اموزشی توی زمینه دیپ لرنینگم …ولی واقعا بعد از حدود ۴۵ ساعت آموزشی ک تا الان دیدم به جرات میتونم بگم درکی که توی این چن ساعت مطالعه مطالب رایگان شما داشتم واقعا خیلی خیلی مفیدتر بوده…انشالله بعد اتمام این دوره در جریانم حتما دانشجوی دوره های تصویری شما هم خواهم بود…خیلی خیلی ممنون بابت زحماتتون
سلام
از اینکه این آموزش به شما کمک کرده و مفید بوده، خوشحالیم.
براتون پیشرفت زیاد و موفقیت در یادگیری عمیق رو آرزومندیم. ✌😊
سلام
خیلی عالی بود مطلبتون. ساده و روان و با مثال و انیمیشن
خیلی خیلی ممنون
کاش کدهای خیلی ساده هم داشت
سلام
خوشحالیم که آموزش شبکه عصبی کانولوشن برای شما مفید بوده.
سپاس 🌹🙏
از شدت خفن بودنتون همینجور موندم عالیییی بود عالییییییییییییییی
به سبک خودتون سپاااااااس 😊🌹🙏
دوستان گرامی ، براتون قلبا آرزوی موفقیت می کنم
بسیار بیان شیوا و عالی دارید . خدا قوت .
هیات علمی دانشگاه آزاد اسلامی
سلام
نظر شما برای ما خوشحالکننده و مایه افتخار هست.
سپاس
سلام ممنونم از مطالب عالیتون من این قسمت از عملگر کانولوشن رو متوجه نشدم که نوشتین هر وقت فیلتر روی قسمتی از ورودی که شبیه به خودش هست عدد روی ماتریس خروجی بزرگ میشه ، چرا؟
سلام
سپاس 🌹🙏
تصور کنید فیلتر 3×3 باشه. حالا این فیلتر روی یک تصویر قرار گرفته و یک ناحیه 3×3 اشغال شده. برای راحتی، بیایید ناحیه 3×3 از تصویر و فیلتر رو تبدیل به بردار کنیم. پس الان دو تا بردار فیلتر و تصویر داریم. حالا یکم مقایسه راحت تر میشه. همه اون ضربی که بین فیلتر و تصویر انجام میشه و بعد ضربها باهم جمع میشن، دقیقا ضرب نقطهای هست. حالا یک سوال ساده؛ ضرب نقطهای چه زمانی عدد بزرگی میشه؟ وقتی دو بردار شبیه هم باشن. دو بردار شبیه یعنی چی؟ یعنی زاویه داخلی کوچکی بین دو بردار وجود داشته باشه.
سلام خدا قوت
جامع و کامل بود
کلی سوال بی جواب منو جواب داد
ممنون
سلام
خداروشکر که جواب سوالهاتون رو پیدا کردید.
سپاس 🙏🌹
با سلام خدمت تیم هوسم
من کلی سایت خارجی و فارسی رو در مورد شبکه عصبی کانولوشن مطالعه کردم و کلی سوال، بی جواب برام موند.
ولی شما در این سایت بسیار ساده و روان تمام مفاهیم مهم و اصلی رو توضیح دادید.
ممنون از شما
باز هم به هوسم سر میزنم
به امید آموزش های بیشتر
سلام
سپاس 🌹🙏
انشالله بتونیم آموزشهای باکیفیتتری آماده کنیم.
ممنونم از سایت خوبتون
سلام
سپاس 🌹🙏
با سلام و احترام
خیلی ممنون بابت این مطالب خیلی خیلی مفید و قابل فهم
اولین باره که دیدم سایتی به این سادگی تونست کل مفهوم رو برسونه 🙂
میشه لطفا در باره شبکه fcn ، نحوه ساخت مدلش ، لایه فولی کانکتد و نکات ریزی که درباره activation ها و فعالساز ها هم بنویسین.
با تشکر فراوان
سلام
سپاس، خوشحالیم که آموزش برای شما مفید بوده. 🌹🙏
درمورد مباحثی که فرمودید، میتونید به دوره بینایی کامپیوتر هوسم مراجعه کنید.
ممنون از توضیحات عالیتون
سپاس 🌹🙏
سلام وقت بخیر ، درود بر شما.
ممنون از شما که وقت و تجربه تون رو برای بقیه هم ب اشتراک میذارین.
مهندس جان در خصوص فولی کانکتد اگر در صورت امکان توضیحاتی بیشتر بفرمائید سپاسگزاریم.
برای مثال فولی کانکتد در لایه آخر برای طبقه بندی داده ها استفاده میشود تعداد لایه ها بسته به کلاس های مورد نظر است. اما سوال اینجا که وقتی در لایه های میانی شبکه استفاده میشود چه نقشی ایفا میکند.
برداشتم تا به این لحظه به این شکل بوده وقتی فولی کانکتد در لایه های میانی هستش صرفا نقش رابط رو داره! بین ورودی خروجی لایه قبلی تا نورون های فعال لایه بعدی!
سلام
سپاس 🌹🙏
تعداد لایهها باتوجه به کلاسها تنظیم نمیشه. تعداد نورونهای لایه فولی کانکتد هست که معمولا تابعی از تعداد کلاسهاست.
در شبکه های عصبی اولیه مثل شبکه عصبی عمیق VGG چند لایه فولی کانکتد در انتهای شبکه وجود داشت. اما بعدا تعداد لایه ها به یک لایه کاهش پیدا کرد. بنابراین، در معماری مدرن، تنها یک لایه فولی کانکتد در انتهای شبکه عصبی کانولوشن وجود داره که اونهم نقش کلاسیفایر رو داره.
درمورد سوال دوم که فرمودید این لایه در میان شبکه استفاده میشه، اکثر معماری هایی که ما دیدیم از این لایه در وسط شبکه استفاده نمیکنن. از ابتدا تا انتهای یک شبکه کانولوشن رو کانولوشن تشکیل داده تا یک استخراج ویژگی خوب از داده ورودی انجام بشه.
اگر هم منظورتون این هست که یک شبکه تماما فولی کانکتد داریم، باید بگم که اونها هم نقش استخراج ویژگی رو دارن. این لایه ها با نگاشت ورودی به فضاهای جدید، سعی میکنن نمایشی بسازن که جداکردن کلاسها برای کلاسیفایر نهایی راحتتر بشه.
سلام مجدد
سوالی داشتم در خصوص کاربرد CNN
آیا جهت ایجاد رگرسیون بین یکسری داده های عددی(یک بعدی) هم میشه از این روش استفاده کرد؟ من از LSTM تونستم استفاده کنم. ولی در مورد CNN نمیدونم. چون گویا ماهیت لایه های کانولوشن در ارتباط با تصاویر که بیشتر از یک بعد دارن هست، درسته؟
سلام
شبکه کانولوشن برای انواع دادهها کاربرد داره. کارهای زیادی وجود داره که از شبکه کانولوشن برای داده یک بعدی (وکتور) استفاده کردند.
چه تغییراتی برای استفاده از کانولوشن در داده یک بعدی لازم هست؟
باید از کانولوشن یک بعدی استفاده کنید. تمام آنچه در این پست گفته شده، براساس فیلتر کانولوشن دوبعدی هست. اما علاوهبر فیلتر دوبعدی، یک بعدی و سه بعدی هم داریم. فریمورک پایتورچ تنسورفلو و کراس هم هرسه نوع فیلتر رو دارند.
سلام. وقت بخیر. در شکل 17 اندازه ی فیلتر در متن سه درسه در تصویر چیز دیگری است. در این تصویر عملا سایز تصویر یک سوم شده ؟
میشه در مورد سایز نهایی فیجر مپ توضیح بدید.
سلام
حق با شماست. سایز فیلتر در متن و شکل همخوانی نداشتند. اصلاح کردیم. ممنون 🌹🙏
توضیح درمورد سایز نهایی فیچرمپ: طبیعتا به ازای هر فیلتری که روی تصویر قرار میگیره و عملیات کانولوشن انجام میشه، یک تصویر یا ماتریس ویژگی در خروجی ساخته میشه. یعنی اگر یک فیلتر 5×5×3 و یک تصویر 100×100×3 داشته باشیم، یک تصویر به ابعاد 100×100 در خروجی تشکیل خواهد شد. البته، لازم هست اینو هم بگیم که این خروجی حتما 100×100 نیست؛ بلکه، بسته به پدینگ و استراید ممکنه سایز اون کوچکتر از 100×100 هم بشه.
حالا اگه بجای یک فیلتر 5×5×3، 1000 تا فیلتر به همین ابعاد داشته باشیم، به ازای هر فیلتر یک خروجی به ابعاد 100×100 ساخته میشه. پس اگه 1000 تا فیلتر داریم، یعنی 1000 تا ماتریس ویژگی 100×100 در خروجی داریم. بهتر بگیم، یعنی یک ماتریس به ابعاد 100×100×1000؛ خب به این ماتریس، فیچرمپ گفته میشه.
امیدواریم با این توضیحات مشکلتون حل شده باشه.
سلام. وقت بخیر . متشکرم. بنده در حال مطالعه ی یک مقاله در زمینه تشخیص ساختار دوم پروتئین با استفاده از یادگیری عمیق هستم در بخشی از مقاله که در مورد فیلتر ها توضیح داده، سوال دارم. امکان دارد بنده رو راهنمایی بفرمائید؟
بخش از متن مقاله رو که سوال دارم می تونم برای شما ارسال کنم؟ چطور؟
متشکرم
سلام
درحال حاضر چنین خدماتی در مجموعه نداریم.
موفق باشید 🌹🙏
چرا انقد خوبه آخه سایتتون؟! :((
هیچ منبعی رو سراغ ندارم که انقدر ساده و شیوا تشریح کرده باشه مفاهیم رو، حتی منابعی که هزینه دریافت میکنند!
مارو گرفتار آموزشاتون کردید رفت …
بهترین هارو برای تیم باانگیزه و پرقدرتتون آرزو دارم
دستمریزاد!
سلام
از خوندن پیام شما بسیار بسیار خوشحال شدیم و خیلی انرژی گرفتیم.
سپاس 🌹🙏
سلام
خدا قوت
واقعا ساده و کامل توضیح داده بدین، خیلی ممنونم ازتون
منتظر آموزش های بیشتر هستیم
سلام
سپاس الیاس عزیز 🌹🙏
ممنون واقعا خیلی مفید بود.
سلام
ممنون از شما بابت کامنت 🌹🙏
با سلام
ممنون
عالی بود
سلام
سپاس 🌹🙏
سلام ممنون بابت آموزش عالیتون بسیار دلسوزانه و روان توضیح دادید.
در پناه حق پیروز و سربلند باشید
سلام
ممنون از شما برای دعای خیر و کامنت
با آرزوی بهترینها برای شما 🌹
سلام
موافق نظر بقیه دوستان مبنی بر اینکه فوق العاده ساده و شفاف و فوقالعاده توضیح داده شده و اصلاً قابل مقایسه با آموزش در سایتهای دیگه نیست کاملاً موافقم. بعنوان یک مدرس، اصلاً اهل نظر دادن در سایتها نیستم ولی اینقدر مطلب از همه نظر جذاب و عالی بود که حیفم اومد نظر ندم.
دست مریزاد و خدا قوت.
سلام
از خواندن پیام شما بسیار بسیار خوشحال شدیم و انرژی گرفتیم.
سپاس 🌹🙏
سلام
عالی بود. دمتون گرم خدا قوت
سلام
سپاس 🌹🙏
این آموزش عالیییی بود. ولی کاش تو حوزه ی متن هم آموزش بذارین.
سلام
سپاس از شما هم برای کامنت و هم برای پیشنهاد 🌹🙏
برای پردازش متن برنامهریزیهایی انجام دادیم و انشالله به زودی آموزش در حوزه متن رو شروع خواهیم کرد.
بسیار عالی بود با زبانی اسان و قابل فهم
خدا قوت
سلام
سپاس 🌹🙏
سلام ممنون از زحمتی که میکشید جهت ارائه مطالب مهم بصورت بسیار روان.
سوالی داشتم.
بعنوان مثال در لایه کانولوشن اول که 32 تا فیچر مپ تولید شد و در لایه ی بعدی 64 تا، آیا هر کدام از 32 فیچر مپ لایه ی اول به 64 تا تبدیل میشود ویا اینکه کلا آن 32 تای قبلی دو برابر شده و به 64 تبدیل میشوند؟
ممنون میشوم اگر طوری توضیح دهید که پاسخ این سوال را مفهومی متوجه شوم.
سلام
باعث خوشحالیه که آموزش برای شما مفید بوده 🌹🙏
جواب کوتاه سوال شما این هست که 32 کانال ورودی، 64 بار به شکلهای مختلف باهم ترکیب میشن و 64 تا کانال خروجی رو میسازن.
اما در ادامه کمی بیشتر درباره سوال شما توضیح دادیم.
سناریوی شما اینطور هست که ورودی 32 کانال دارد و خروجی هم 64 کانال. یعنی این لایه 64 فیلتر دارد.
اما سوال شما این هست که اینها چطور تولید میشن؟
جواب: 64 فیلتر داریم. هر فیلتر ما 32 کانال دارد. یعنی به اندازه ورودی. حالا هربار یک فیلتر برمیداریم و در ورودی که 32 کانال است کانوالو میکنیم و درنتیجه یکی از 64 کانال ساخته میشود. یعنی، 32 کانال باهم ترکیب میشن و یک خروجی میسازن.
سوال بعدی: یعنی وقتی 64 تا فیلتر داریم، 64 بار این ورودی باهم ترکیب میشه؟
جوب: بله، دقیقا. اما هربار یک فیلتر کانولوشنی برمیداریم و چون متنوع هستن، به هرکدوم از این 32 صفحه ورودی یک وزن متفاوتی داده میشه و بعد باهم جمع میشن.
سلام
واقعا خدا قوت
من از اینهمه مباحث عالی همدا با جزئیات به حیرت اومدم…خیلی وقت بود در سایتها و مقالات مختلف به دنبال جزییاتی مثل تفاوت معنایی فیلتر و کرنل بودم که یا مطلب مناسبی پیدا نمیکردم یا گفته میشد که این دو مفهوم کاملا یکسان هستند.امروز که یک روز به دفاع پایان نامه بنده مونده و با سایت شما آشنا شدم خیلی خدارو شکر کردم و برای شما آرزوی موفقیت و سلامتی دارم و پیشرفت در کارهاتون رو دارم.
سلام
خیلی متشکرم از مطلب و بیان خوبتون.
این سوال من هم بود که با پاسخی که فرمودید متوجه شدم.
خدا قوت
عالی بود . من ویدئو هاتون رو هم خریدهم . هرچه فیلم اموزشی توی ساییتون درباره شبکه عصبی و یادگیری عمیق و پایتون و هوش مصنوعی باشه میخرررررممم
سلام
ممنون 🌹🙏
واقعا از اینکه انقدر ازمون حمایت میکنید صمیمانه سپاسگذاریم. ❤
سلام
خدا قوت
خیلی ممنون از وقتی که میذارید و این آموزشهای خوب رو تولید میکنید
سلام
سپاس علی عزیز 🌹🙏
بسیار عالی.
مطالب رو بسیار روان و همراه با فهم عمیق توضیح دادید.
به امید موفقیتهای بیشتر برای تیم شما.
منتظر پستهای بعدی شما هستیم و کارتون رو دنبال خواهیم کرد.
سلام
سپاس بابت این همه انرژی مثبت 🌹🙏
عالی بهتر از هر آموزش دیگه ای که دیدم
سلام
سپاس 🌹🙏
فوق العادههههههههه بود
ممنون
سلام
خیلیییی ممنون 🌹🙏😊
سلام
برای پایان نامه میخوام از مطالب سایتتون در مورد کانولوشن استفاده کنم میشه بگین منابعشون رو از کجا استفاده کردین؟ چون باید کتاب یا مقاله معتبر بهش رفرنس داده بشه. با تشکر
سلام حسین عزیز،
این پست، ترجمه خط به خط از یک منبع نیست. از منابع مختلفی استفاده کردیم. اما، این کتاب، منبع خوب و معتبری هست که ما ازش استفاده کردیم. لینک
آرزوی موفقیت برای شما در پایاننامه 💪❤
از اینکه منابع و اطلاعات و در اختیار میزارید تشکر میکنم واقعا سایت تون عالی هست بیان ساده و روان برای این مباحث فقط در این سایت هست.
سلام
واقعا عالی بود من موضوع ارائه ام همین شبکه ها بود کلی سایت دیدم ولی چیز خوبی گیرم نیومد تا این که سایت شما رو دیدم و دیدم که واقعا مطالب عالی هستند و تونستم ارائه رو بدم
ممنون
سلام
سپاس احمد عزیز 🌹🙏
این برای ما یک دستاورد بزرگ هست که شما به کمک این آموزش تونستید ارائه رو پشت سر بگذارید.
هنوز باورم نمیشه یه آموزش فارسی به این شفافی و کاملی پیدا کردم.
دست مریزاد
سلام
سپاس 🌹🙏
انشالله بتونیم بهتر از اینها رو آماده کنیم.
با سلام
من هم مطالب زیادی در این موارد تا الان مطالعه کردم ولی بنظرم روان و کامل مطالب بیان شده است از زحمات شما تشکر را دارم
با آرزوی توفیقات روز افزون.
سوالی هم داشتم در بسیاری از مقالات برای یادگیری عمیق و CNN صرفا پردازش تصویر گفته می شود آیا اگر دیتاست بزرگی(غیر از تصاویر و عمدتا فیلدهای ) از اطلاعات سهم یا بانکی داشته باشیم نمی شود از قابلیتهای یادگیری عمیق و CNN یا RNN استفاده نمود لطفا راهنمایی کنید.
ممنون
سلام
سپاس 🌹🙏
شبکههای CNN و RNN ابزارهایی هستند که صرفا محدود به یک زمینه یا کاربرد نمیشن. بهعنوان نمونه، همه شبکه CNN رو با کاربرد در پردازش تصویر و RNN رو در متن دیدیم. اما شبکه CNN هم در متن و هم در صوت کاربرد داره. در مورد پیشبینی سهام بورس، شبکه های بازگشتی مثل RNN LSTM GRU بسیار کاربرد دارند. مثلا ما در این پست درباره سهام بورس و LSTM صحبت کردیم و یک پروژه انجام دادیم.
سلام،
نحوه توضیح و مثال ها به اندازه ای خوانا بود که باعث شد چند ساعتی بشینم و کامل تمام آموزش رو از اول مطالعه کنم. خسته نباشید و خدا قوت به خاطر وقتی که میذارید و این مطالب رو آماده می کنید. این نوع توضیح دادن نشان دهنده درک بالا و عمقی شما در این زمینه می باشد. امیدورام که این آموزش ها با ویدیو هم همراه باشه. و به عنوان پیشنهاد هم میتونید یک بخش به سایت اضافه کنید که در مورد مقالات هات و روز دنیا صحبت کنید و توضیح بدید. مقالاتی مثل BERT , MT_DNN, GPT3 و … این بخش باعث میشه افراد مختلف وب سایت شما رو همیشه چک کنند و به روز باشند.
تشکر از زحماتتون
سلام
سپاس 🌹🙏
بسیار خوشحالیم که آموزش نظر شما رو جلب کرده. پیشنهاد شما بسیار عالی هست. خودمون هم بسیار علاقهمندیم که از مقالات روز صحبت کنیم.
خیلی خیلی عالی بود
توضیحات واضح و روان و بسیار مفید بود
سلام
سپاس 🌹🙏
درود بر مجموعه و سایت بی نظیرتون
سلام
سپاس 🌹🙏
عاااااااااااالی . بی نظیییییییییییییییر
مرسی ازتون واقعا
ای کاش در مورد اونایی که در انتهای پست معرفی کردید هم توضیح بزاید.
سلام
سپاس 🙏🌹
درمورد مطالب انتهای پست هم انشالله در همین پست توضیح خواهیم داد.
سلام، خیلی متشکرم بابت توضیح کامل و بیان زیبای شما. به جرات میتونم بگم یکی از کامل ترین داکیومنت هایی بود که برای CNN خوندم، چه به زبان فارسی و چه انگلیسی. موفق باشید
سلام
سپاس بابت کامنتی که گذاشتید و البته بابت این همه انرژی که دادید. 🌹
برای این پست زمان زیادی گذاشته شده و خوشحالیم که با منابع انگلیسی مقایسه شدیم. 🙏
واقعا فوق العاده هستید
سلام
سپاس بابت انرژیای که به ما میدید 🌹
خیلی عالی
خیلی ممنون
سلام
سپاس 🌹
سلام. استاد میشه لطفا کد شبکه ها رو هم قرار بدید که با تئوری مقایسه کنیم؟ ممنون
سلام
انشالله در یک پست دیگه اینکار رو میکنیم.
خیلی خوب می نویسید لطفا در مورد شبکه های پیشرفته مثل alexnet ,mobilenet,google netو یادگیری انتقالی هم مطلب بگذارید.از پایه شروع کردن خوب هست ولی مطالب پایه زیاد هست.مطالب پیچیده تر رو بیان کنید که کم تر سایت ها روش کار کردن
سلام
سپاس 🌹
تشریح شبکه های معروف کانولوشنی هم در برنامه ما قرار داره. از پایه شروع کردیم و انشالله تا مطالب پیشرفته پیش خواهیم رفت…
از شما بابت پیشنهادتون ممنونیم.
ممنونم از سایت مفیدتون. واقعا بیان قابل فهمی دارید. لطفا بخش های بعدی رو زودتر قرار بدید که استفاده کنیم. خدا قوت
سلام
سپاس 🌹
نگارش شبکه عصبی بازگشتی شروع شده و انشالله طی روزهای آینده منتشر میشه.