
الگوریتم k means
بهنام خدا، سلام… در جلسه ششم از آموزش یادگیری ماشین رایگان به الگوریتم خوشه بندی k-means خواهیم پرداخت. الگوریتم خوشه بندی K-means یکی از متداولترین و سادهترین روشهای خوشهبندی در یادگیری ماشین و دادهکاوی است. از این الگوریتم برای تقسیم دادهها به K گروه یا خوشه استفاده میشود. جلسه جذابی است، با هوسم همراه باشید…
الگوریتم k means چیست؟
بیایید در یک جمله با الگوریتم k means آشنا شویم:
الگوریتم kmeans یک روش خوشهبندی داده است که در دسته روشهای بدون ناظر قرار میگیرد.
جمله بالا چند واژه کلیدی دارد:
- بدون ناظر: با مفهوم بدون ناظر در جلسه دوم یادگیری ماشین آشنا شدید. یعنی از لیبل یا برچسب خبری نیست!
- خوشه بندی: یعنی گروهبندی یا دسته دسته کردن دادهها. در واقع شبیه به همان دستهبندی در باناظرهاست. مثلا شکل زیر خوشه بندی دادهها به دو خوشه است.

درادامه میخواهم چند مثال از خوشهبندی بیاورم که بیشتر با این مفهوم آشنا شوید.
جدا کردن یک جمعیت به دو گروه با خوشهبندی
تصور کنید صد نفر آدم پیش روی شماست و من به شما گفتهام که اینها را به دو گروه تقسیم کن. احتمالا شما میگویید، خب بر چه اساس یا خصوصیتی این کار را انجام دهم؟ من هم میگویم خودت میدانی! بعد شما میگویید: آخه… بعد من میگویم آخه آخه نگو دیگه، اینها رو جدا کن کار داریم!
اینکه من نمیگویم افراد چگونه جدا شوند، یعنی به شما لیبل یا برچسب ندادم. با وجود اینکه انتظار دارم شما این افراد را گروهبندی، خوشهبندی یا دستهبندی کنید. این یک نمونه مثال واضح از خوشهبندی است. میبینید در جمعیت، هم مرد هست و هم زن. راه حل احتمالی شما برای گروه بندی، جنسیت هست. پس میتوانید به این شکل گروهبندی کنید.
جدا کردن توپهای رنگی با خوشهبندی
تصور کنید، یک سبد توپ رنگی به یک کودک بدهیم و بگوییم توپها را گروهبندی کن. عجیب نیست کودک بدون آخه، سخنرانی، تحلیلهای فراکارشناسی خوابگاهی با پیژامه و زیرسوال بردن مساله از بنیان، این کار را انجام بدهد! میبیند توپها رنگهای مختلفی دارند و میتواند آنها را براساس رنگ جدا کند. درحالیکه اول کار، ما بدون اشاره به رنگ و خصوصیات دیگر، فقط یک سبد توپ به او داده بودیم.
بسیارخب دیگر مقدمات کافی است و برویم سراغ اصل مطلب و ببینیم الگوریتم خوشه بندی k means دقیقا چیست.
الگوریتم خوشه بندی k means زیر ذرهبین
برای اینکه بهتر الگوریتم k means را یاد بگیرید، یک مثال برای شما درنظر گرفتم. کل این الگوریتم را با همین مثال پیش میبرم. خوشبختانه مثال ما شامل دو ویژگی است (x,y) و بنابراین میتوانیم آن را رسم کنیم.

با رسم نمودار کاملا واضح است که سه خوشه داریم.
الگوریتم خوشه بندی k-means یک سلسله مراحل تکراری دارد. از این به بعد شروع میکنم به تشریح تک تک مراحل الگوریتم k-means …
مرحله 0: تعیین تعداد خوشه (K)
مرحله صفر این است که تعداد خوشه باید توسط کاربر تعیین شود. ما باید تعیین کنیم که میخواهیم دادهها به چند خوشه تقسیم شوند. برای این مثال میخواهیم سه خوشه داشته باشیم (K=3). اجازه دهید، همینطور که مرحله به مرحله پیش میرویم، بلوک دیاگرامی هم برای الگوریتم k means بسازیم.

مرحله 1: تعیین مرکز خوشه
در مرحله 1 باید به اندازه تعداد خوشه (3)، مرکز خوشه تعیین کنیم. مرکز خوشه یعنی چه؟ یعنی…
نماینده، کاپیتان یا مرجع آن خوشه!
همه دادهها به کاپیتانها نگاه میکنند و بعد طی فعل و انفعالی که بعدا توضیح میدهم به یکی از کاپیتانها ملحق میشوند. این مرکز خوشهها را بهصورت تصادفی انتخاب میکنیم. برای این مثال، مثلا نقطههایی در فضای دوبعدی…
چون ما سه خوشه داریم، پس به صورت تصادفی سه نقطه به عنوان مرکز خوشه انتخاب میکنیم. در تصویر زیر مراکز خوشه را با ستاره نشان دادهایم. سه خوشه ما به ترتیب در موقعیتهای زیر قرار دارند:
- خوشه سبز: (2,7) = c1
- خوشه قرمز: (3,7) = c2
- خوشه زرد: (4,7) = c3

نکته 1: اگرچه میگوییم که مراکز خوشه را تصادفی انتخاب میکنیم، اما اینطوری هم نیست که دادههای ما در ∞- باشد و ما مراکز را در ∞+ انتخاب کرده باشیم. هرچه مراکز به دادهها نزدیکتر باشند، بهتر است.
این هم از بلوک دیاگرام الگوریتم خوشه بندی k-means تا اینجا:

فعلا مراکز خوشهها، تک و تنها هستند و اعضایی ندارند. در مرحله بعدی قرار است هریک از این مراکز خوشه، عضوگیری کنند. شاید تجربه کرده باشید، در بازیهای گروهی مثل فوتبال که وقتی تعداد بازیکنان زیاد است، ابتدا چند نفر سرگروه میشوند. این سرگروهها همان مراکز خوشه هستند که ابتدا تنها هستند. بعد براساس معیارهایی شروع میکنند به جذب افراد و اضافه کردن به گروه یا خوشه خودشان… حالا ما هم کاپیتانها را مشخص کردهایم، میخواهیم برویم عضوگیری کاپیتانها را تماشا کنیم.
مرحله 2: فاصلهسنجی و خوشهبندی
این مرحله مهم شامل دو قسمت فاصلهسنجی و خوشهبندی است. ابتدا فاصلهسنجی؛ باید فاصله هر داده با مراکز خوشه محاسبه شود. مثلا به تصویر زیر نگاه کنید؛ فاصله این داده با هر سه مرکز سنجیده شده است.

این فاصله سنجی براساس فاصله اقلیدسی انجام میشود. یعنی فرمول ساده زیر:
![]()
منظور ما از pi یا (xi,yi) یک نمونه داده از مجموعه دادههای ماست. همچنین، ck یا (ckx,cky) به مرکز خوشه k اشاره دارد. بیایید فاصله مرکز خوشهها را با داده pi=(xi,yi)=(1,3) حساب کنیم. پیشنهاد میکنم اول خودتان محاسبه کنید و بعد ادامه آموزش را مطالعه کنید.
باتوجه به مقدار نقطه (1,3) و همچنین مختصات سه مرکز (2,7)، (3,7) و (4,7) فاصله اقلیدسی به صورت زیر محاسبه میشود:

بعد از اینکه فاصله داده با مراکز خوشه محاسبه شد، باید مشخص کنیم که این داده به کدام خوشه تعلق دارد. چگونه؟ ساده است:
یک نمونه داده به خوشهای تعلق دارد که تا مرکز آن خوشه کمترین فاصله را دارد.
حالا، چون نقطه (1,3) به مرکز خوشه 1 (سبز) نزدیکتر است، پس به این خوشه تعلق دارد. میتوانیم رنگ داده را به رنگ خوشه در آوریم که بفهمیم هر داده به کدام خوشه تعلق دارد. به این شکل:

همچنین، سه لیست خالی برای سه خوشه میسازیم تا دادههای خوشه بندی شده را در این لیست قرار دهیم. تا الان داده (1,3) در خوشه 1 قرار گرفته است:
s1 = [(1, 3)]
s2 = [ ]
s3 = [ ]
لیست دادههای هر خوشه را در متغیر s قرار دادهایم.
تکرار فاصلهسنجی و گروهبندی برای همه دادهها
این روال باید برای تک تک دادههای موجود انجام شود. مثلا در شکل زیر، یک داده دیگر نشان داده شده که این بار فاصله کمتری تا مرکز خوشه 3 (زرد) دارد و بنابراین به خوشه 3 اختصاص مییابد.

حالا انیمیشن زیر را ببینید که یکی یکی دادهها فاصلهسنجی و گروهبندی میشوند.

سی چهل بار انیمیشن بالا را ببینید تا کامل متوجه شوید. خوشههای ما هم به شکل زیر درآمدهاند:
s1=[(0.5, 2), (1, 1), (1, 1.5), (1, 2.5), (1, 3), (1.5, 2), (2, 2.5), (2, 3), (2.5, 3.5)]
s2=[(3, 3), (3, 3.5), (3, 4), (3.5, 4)]
s3=[(4, 5), …]
انصافا تا اینجا خیلی راحت بود. از اینجا به بعد هم راحت هست. قبل از اینکه سراغ بخش بعدی برویم، بلوک دیاگرام الگوریتم خوشه بندی k-means را تا اینجا ببینیم.

مرحله سوم: آپدیت مرکز خوشه ها
مرحله سوم، آپدیت مرکز خوشه هاست. قبلا گفتیم که مرکز هر خوشه نماینده آن خوشه هست. اتفاقا از اسمش هم مشخص هست که قرار است مرکز یک خوشه باشد. اما الان اگر به نتیجه گروهبندی (تصویر پایین) نگاه کنید، چندان ارتباطی بین اعضای یک خوشه و مرکز خوشه نمیبینید. به نظر میرسد اعضای هر خوشه از عملکرد نماینده خوشه راضی نیستند و میخواهند آن را عوض کنند. به نظر شما بهترین راه برای ایجاد یک مرکز خوشه مناسب چیست؟

بهترین راه ایجاد یک مرکز خوشه جدید:
میانگینگیری از اعضای خوشه
اگر میانگین اعضای موجود در هر خوشه را حساب کنیم، یک مرکز خوشه جدید خواهیم داشت. بیایید این بخش را فرموله کنیم:

حالا بیایید برای خوشه 1 این کار را انجام دهیم. در رابطه زیر، میانگین 9 داده موجود در خوشه 1 حساب شده است:

روال بالا باید برای تک تک خوشهها تکرار شود.
حالا بیایید روی شکل مرکز خوشه جدید را نشان دهیم:

حالا بهتر شد؛ الان نماینده هر خوشه همصدا با اعضای خوشه خود هست. سوسماسسس!
الگوریتم k-means تمام شد؟!
بله تمام شد! 😀 اما یک نکته مهم را هنوز نگفتم که اتفاقا ساده هم هست. اینکه ما باید به اعضای یک خوشه حق بدهیم که بتوانند مهاجرت کنند و به سادگی (بدون نیاز به ویزا، عوارض خروج از کشور و طرح صیانت از نخبهها) به سایر خوشهها مهاجرت کنند. ممکن است بعد از آپدیت مراکز خوشه، بعضی از دادهها دیگر کمترین فاصله را با مرکز خوشه خود نداشته باشند. به دادهای که با فلش نشان دادهایم، نگاه کنید؛ کاملا مشخص است که دیگر با مرکز خوشه سبز کمترین فاصله را ندارد.

پس دوباره باید فاصله سنجی و خوشه بندی کنیم. یعنی همان مرحله دوم را دوباره تکرار کنیم:

حالا که گروهبندی آپدیت شده، ممکن هست بازهم مراکز خوشه مناسب نباشند. درنتیجه بازهم باید مرحله سوم تکرار شود:

میبینید؟ مرحله دوم (فاصلهسنجی و گروهبندی) و سوم (آپدیت مرکز خوشهها) را دوباره تکرار کردیم. اما مساله این است که ما آروم نمیگیگیریم! آنقدر مرحله دوم و سوم را تکرار میکنیم تا بالاخره به مرحله پایدار برسیم و دیگر دادهها خوشههای خود را عوض نکنند. اگر مهاجرت نداشته باشیم، مراکز خوشه (نمایندهها) هم تغییر نمیکنند و الگوریتم k means به پایان میرسد. و اینگونه بود که اعضا و مراکز خوشه در صلح و صفا به زندگی خود ادامه دادند…
انیمیشن و فلوچارت الگوریتم خوشه بندی K-means!
بیایید انیمیشنی ببینیم از فرآیند خوشه بندی K-means؛ در شکل زیر، میتوانید ببینید که در چند تکرار بالاخره مرکزها در موقعیت خوبی قرار میگیرند و دیگر دادهها عضویت خود را عوض نمیکنند.

اما در پایان بگویم که بلوک دیاگرام الگوریتم k-means به صورت زیر میشود:

خب لوزی یک شرط هست که چک میکند آیا این فرآیند kmeans ادامه داشته باشد یا خیر. اما چرا نوشتهام “تابع هدف مینیموم شده”؟ اصلا تابع هدف چیست؟ برویم ادامه…
تابع هدف در الگوریتم k means
من گفتم این الگوریتم تا آنجایی باید ادامه پیدا کند که اعضا تغییر گروه ندهند و مراکز خوشه هم جابجا نشوند. اما این جمله من کیفی است و باید فرمولی برای این عبارت بسازم. تابع هدف، یک تابع کلی است که میتواند میزان خطا را در خوشهبندی به ما نشان دهد. ما آنقدر ادامه میدهیم تا تابع خطا به حداقل مقدار برسد (یعنی صفر شود). اگر هم صفر نمیشود، مقدار خیلی کمی داشته باشد. یا اینکه ببینیم مثلا تابع هدف مقدارش کاهش پیدا کرده، اما دیگر بیشتر از این کم نمیشود و بیخود الگوریتم ما درحال تکرار است. بسیارخب، دراین حالت هم میتوانیم اجرای الگوریتم را متوقف کنیم.
فرمول تابع هدف در الگوریتم k-means چیست؟ از فرمول کله گنده زیر استرس نگیرید! چیزی نیست، الان دخلش را درمیآوریم:

واقعیت این است که شما فرمول بالا را قبلا در همین آموزش دیدهاید! آن سیگمای داخلی فاصله دادههای یک خوشه را با مرکز همان خوشه محاسبه میکند. زمانی J به کمترین مقدار میرسد که هر دادهای دقیقا در خوشه درست خودش قرار بگیرد. اگر داده 1 اشتباها در خوشه 3 باشد، نتیجه این میشود که مقدار J افزایش مییابد.
خب به پایان رسیدیم. مدتی بود وبلاگ ننوشته بودم. این پست هم یک عالمه کدنویسی و نقاشی داشت و حسابی وقتگیر شد. امیدوارم همه این کارها منجر به این شود که الگوریتم k means را راحت متوجه شوید. وبلاگ نوشتن را دوست دارم، اما کارهایم زیاد شده و کمتر وقت وبلاگ نوشتن دارم. تلاش میکنم در سال 1401 شش پست بنویسم.
مطالب زیر را حتما مطالعه کنید

یادگیری ماشین بدون ریاضی و کدنویسی

پیشنیازهای یادگیری ماشین

یادگیری ماشین چیست
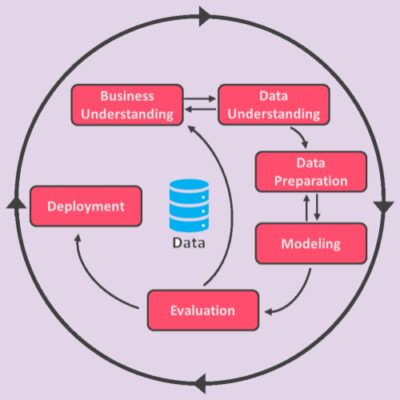
فرآیند کریسپ (CRISP)

آموزش سایکیت لرن

آموزش یادگیری ماشین رایگان
72 دیدگاه
به گفتگوی ما بپیوندید و دیدگاه خود را با ما در میان بگذارید.
بسیار عالی بود، خصوصا مدل توضیح دادنتون. خیلی بامزه بود واسه آروم نمیگگیریم کلی خندیدم!
واقعا عالی
دست تون درد نکنه
ایشالله هر چی آرزو دارین بهش برسین
بی نظیر بود تدریس و انمیشن ها و درخواست دارم که K-mediods هم توضیح بدید به همین شکل خیلی عالی بود.
سلام خسته نباشید
خیلی مفید و ساده بیان شد
خدا خیرتون بده
سلام
خوشحالیم که آموزش Kmeans برای شما مفید بوده.
ممنون بابت دعای خیر و کامنت 😊🙏
توضیحات و انیمیشن ها عااالی بود…دم شما گرم و خداقوت…
ممنون 🌼🙏
بسیار بسیار ساده و روان توضیح داده بودید . من در سایت های مخلف مطالعه کردم ولی با این مقاله کاملا متوجه موضوع شدم. سپاسگزارم
باعث خوشحالی هست که با آموزش هوسم ارتباط برقرار کردید.
موفق باشید ✨
مثل همیشه عالی و روان.
سپاس از توجه شما🌹
بسیار توضیح روان برای من مبتدی.دمت گرم
چقدر ساده و واضح توضیح دادید. خیلی عالی بود . من کلی مطلب آموزشی خوندم ولی درست متوجه نشدم تا اینکه متن آموزشی شما روخوندم. خلاصه اصا یه وضعی شدم. عالی عالی عالی
خوشحالیم که آموزش کمکتون کرده.
موفق باشید 🌺
فوق العاده بود احسنت به این اموزششششس
ممنون 😊