
رگرسیون لجستیک
در پنجمین جلسه از آموزش یادگیری ماشین رایگان، میخواهم شما را با رگرسیون لجستیک آشنا کنم. رگرسیون لجستیک یک مدل دسته بندی (Classification) است. حتما از جلسه دوم با موضوع انواع یادگیری در یادگیری ماشین میدانید که دسته بندی یکی از زیرشاخههای یادگیری با ناظر است. این جلسه بسیار جذاب است. با هوسم همراه باشید…
دسته بندی یا کلاس بندی یا طبقه بندی
ابتدا بیایید کمی درباره کلاس بندی صحبت کنیم. بعد برویم سراغ موضوع اصلی، یعنی رگرسیون لجستیک. همانطور که گفتم مدل رگرسیون لجستیک از دسته روشهای Classification است. در فارسی بجای Classification کلماتی مانند کلاس بندی، طبقه بندی یا دسته بندی بهکار میرود. طبیعتا دسته بندی و طبقه بندی بهتر از کلاس بندی است. بسیارخب، همین ابتدا یک سوال مهم! در فصل قبلی به رگرسیون از زیرشاخههای یادگیری باناظر پرداخته شد. چه تفاوتی بین کلاسبندی و رگرسیون وجود دارد؟

تفاوت دسته بندی و رگرسیون چیست؟
در رگرسیون، هدف تخمین یک تابع برای رسیدن به خروجی با مقدار واقعی از روی داده ورودی است. منظور از مقدار واقعی، مقدار پیوسته است (مانند 1.2، 1.75، 3.892- و غیره). اما در بحث دسته بندی، هدف تخمین یک تابع برای رسیدن از ورودی به خروجی مطلوب گسسته است. دیگر این خروجی مطلوب، اعداد پیوسته یا واقعی نیست. بلکه، خروجی مجموعهای از اعداد گسسته (مانند 0، 1، 2 و غیره) است. این اعداد همان دسته ها هستند. مثلا در شکل زیر، دادههایی از میزان خواب و مطالعه دانش آموزان داریم و میخواهیم بدانیم کدام دانشآموزان در امتحان قبول میشوند و کدام نه؟ یعنی خروجی مطلوب ما میتواند شامل دو عدد 1 (قبولی) و 0 (مردودی) باشد. شکل زیر، نمودار قبولی/ردی دانشآموزان برحسب میزان مطالعه و خواب را نشان میدهد.

ما میخواهیم از روی نمودار بالا، مثلا به مرزی به شکل زیر برسیم. این خط را دیگر نمیتوان با رگرسیون جلسه قبل بدست آورد. این خط جداکننده مرز دو دسته است. بالاییها قبولی و پایینیها ردی…

بیایید در قالب مثال بیشتر با دسته بندی آشنا شویم.
چند نمونه مثال دسته بندی
مسائل زیادی در یادگیری ماشین و دنیای امروزمان وجود دارند که مبتنی بر دسته بندی هستند. چند نمونه جالبش را برای شما آوردم:
- جدا کردن تخممرغ آبپز از خام براساس وزن آنها: وزن هر تخممرغ را داریم. میتوانیم روی نمودار بیندازیم و بعد مرز بین این دو دسته را تعیین کنیم.
- دسته بندی وضعیت موتور به دو حالت عادی و غیرعادی براساس میزان دما و فشار: دو عامل مهم دما و فشار به ما کمک میکنند که تشخیص دهیم موتور حالت عادی دارد یا غیرعادی.
مورد 1 و 2 شبیه همان مثال قبولی دانشآموزان براساس میزان مطالعه و خواب هست. یکسری داده عددی که میتوانیم مانند شکل 5 در قالب یک جدول یا اکسل آنها را ذخیره کنیم. به این نوع دادهها، دادههای ساختارمند (Structured) گفته میشود. اما در ادامه میخواهم شما را با چند نمونه جالب از دسته بندی آشنا کنم.
دسته بندی در سایر زمینههای تحقیقاتی
در موارد زیر، اگرچه بازهم دسته بندی داریم، اما داده شکل دیگری دارد. ببینید:
- جدا کردن صدای زن و مرد: بازهم دو دسته داریم که این بار دادههای ورودی صدا هست. صرفا جهت آشنایی به شما میگویم که وقتی داده صوت هست، یعنی وارد قلمرو پردازش گفتار شدیم.
- جدا کردن ماهی قزلآلا و خاویاری براساس شکل آنها: یعنی این دو دسته را براساس تصویر آنها باید از هم جدا کنیم. چون داده ورودی تصویر است، وارد قلمرو پردازش تصویر شدیم.
- دسته بندی کامنت مثبت و منفی برای فیلمها: برای یک فیلم کامنتهای زیادی گذاشته شده، میخواهیم آن را به دو دسته مثبت (تایید فیلم) و منفی دسته بندی کنیم. داده ورودی متن است و این بار یادگیری ماشین و دسته بندی مهمان پردازش متن هستند.
شاید برای شما سوال شده باشد که چگونه متن و استرینگ را دستهبندی میکنیم؟ ما در یادگیری ماشین با اعداد و معادلات سروکار داریم ولی اینها که متن هستند! طبیعتا برای تصویر و صوت هم همینطور است. به این دادهها، دادههای غیرساختارمند (Unstructured) گفته میشود. این نوع دادهها را باید ابتدا به یکسری اعداد تبدیل کنیم و بعد عمل دسته بندی را انجام دهیم. چگونه این کار تبدیل متن/تصویر/صوت به عدد انجام میشود؟ اینها هرکدام درس مربوط به خود را دارد که باید مطالعه کنید و آشنا شوید. موضوع بحث ما نیست.

بسیارخب، تفاوت بین دسته بندی و رگرسیون را گفتیم. تفاوتهای دیگری هم وجود دارد که کمکم در ادامه توضیح خواهم داد. برویم رگرسیون لجستیک را شروع کنیم.
رگرسیون لجستیک (Logistic Regression)
رگرسیون لجستیک یا logistic regression یک مدل معروف دسته بندی دو کلاسه است. ممکن است نام رگرسیون لجستیک باعث تعجب شما شود. کلمه رگرسیون دارد، اما دسته بندی است؟ بله، این مدل بسیار شبیه رگرسیون خطی است. تفاوتهای ریزی دارد که یکی از آنها در تابع اتلاف است. اگر یادتان باشد، در رگرسیون از تابع اتلاف MSE استفاده شده بود. اما اینجا تابع اتلاف دیگری وجود دارد که مناسب کار دسته بندی است. تابع اتلافی بنام cross entropy که به موقع درباره آن توضیح خواهم داد.
بیایید ابتدا درباره داده در دسته بندی صحبت کنیم.
داده در دسته بندی
ما شکل دادهها را در یادگیری باناظر قبلا در فصل رگرسیون دیدهایم. دادههایی به شکل (X,y) که شامل داده ورودی/خروجی است. هر داده ورودی Xi میتواند n-بعدی باشد ([x1, x2, …, xn]=Xi). برای سادگی خیلی مثالها را با یک یا دوبعد جلو میبریم. اما فراموش نکنید، دادهها در یادگیری ماشین معمولا ابعاد بالاتر از دو یا سه بعد دارند. بنابراین، داده ورودی X بسیار شبیه داده ورودی در رگرسیون است.
اما خروجی y متفاوت با رگرسیون است و پیوسته نیست. بلکه، عدد گسسته است که مقدار آن 0 یا 1 است. این دو عدد نشان میدهند که رگرسیون لجستیک یک دسته بندی دو کلاسه است. حتما میدانید که به خروجی مطلوب، برچسب یا لیبل گفته میشود (اگر نمیدانید پست یادگیری ماشین چیست را مطالعه کنید). حال همه دادههایی که مقدار y آنها برابر با یک عدد باشد را میتوان به عنوان یک کلاس قلمداد کرد. یک شمای کوچک از دیتاستی برای دسته بندی دوکلاسه را در شکل زیر میبینید. هر سطر یک داده هست و ستون آخر همان برچسب هست. برای بعضی دادهها یک و برای یکسری هم صفر است. دو ستون اول ویژگیها هستند.

ترسیم داده همراه با برچسب برای دسته بندی
اجازه دهید یک نمونه دیتاست با یک ویژگی و برچسبهای آن را در فضای دوبعدی ترسیم کنیم. به شکل زیر نگاه کنید؛ دادههای یک بعدی همراه با برچسب y (محور عمودی) به نمایش درآمدهاند. همانطور که میبینید برای هر داده Xi یک برچسب با مقدار 0 یا 1 وجود دارد. آیا میتوانیم یک رگرسیون خطی برای این مساله آموزش دهیم؟ به نظر میرسد دادهها روی یک خط راست قرار ندارند. بنابراین، احتمالا با برازش یک خط راست نتیجه مناسبی حاصل نمیشود. موافقید؟ اگر موافق نیستید، همین جا ترمز دستی را بکشید و روی کاغذ این نقطهها را بکشید. بعد بهترین خط راستی که میتوانید را بکشید. آیا این خط فاصله نزدیکی به همه نقاط دارد؟

رخنمایی تابع پله
توزیع داده ها شبیه به تابع پله نیست؟ به شکل زیر نگاه کنید؛ دادههایی که روی پله بالایی (راست) قرار دارند، داده کلاس 1 محسوب میشوند. دادههایی هم که روی پله پایینی قرار دارند، بهعنوان کلاس 0 شناخته میشوند. اصلا میتوان کار را راحتتر کرد. اگر حتی یک آستانه (لبه بالارونده پله) پیدا کنیم، کار سادهتر هم میشود! چون کافی است مقدار ورودی را با آستانه مقایسه کنیم، اگر از آستانه بزرگتر بود، کلاس 1 و اگر هم کوچکتر بود مقدار 0.

حالا چطور میتوانیم با یادگیری ماشین یک تابع پله مناسب برای این داده بیابیم؟ مثلا یک تابع به شکل زیر آماده کنیم و بعد با تابع اتلاف و گرادیان کاهشی مقدار پارامترهایش (w و b) را بیاییم. چطور است؟
![]()
ایده بدی نیست! ولی یک مشکل بزرگ داریم. تابع پله گسستگی دارد و مشتقپذیر نیست. از جلسه گرادیان کاهشی و رگرسیون خطی یادتان میآید که کل فرآیند آموزش مدل یادگیری ماشین برپایه گرادیان کاهشی و مشتق است؟ چون تابع پله مشتقپذیر نیست، به مشکل میخوریم. آیا تابعی داریم که عملکردی شبیه تابع پله داشته باشد و مشتقپذیر هم باشد؟ تابع سیگموید.
تابع سیگموید در رگرسیون لجستیک
به نمودار و رابطه تابع سیگموید در شکل زیر دقت کنید.

در نمودار بالا، کاملا مشخص است که تابع سیگموید شبیه تابع پله هست. حال اگر بخواهیم حالت گذار در تابع سیگموید را به تابع پله نزدیکتر کنیم، کافی است ورژنهای وزندار آنها را استفاده کنیم (نمودار زیر).

به ضریب w در رابطه سیگموید دقت کنید. با بزرگتر کردن آن، بیشتر شبیه پله میشود. پس خوب است که به مدل یادگیری ماشینمان آزادی عمل بدهیم که خودش این مقدار w را تعیین کند. راستی، اگر یک مقدار b هم کنار wx- میگذاشتیم، آزادی عمل بیشتر میشد و نمودار ما میتوانست روی محور افقی جابجا شود. رابطه زیر، تابع نهایی رگرسیون لجستیک ما است:

پس یک مدل جدید ساختیم که الان میتوانیم با گرادیان کاهشی و تابع اتلاف مانند رگرسیون خطی آنرا آموزش دهیم. راستی، حالا که صحبت از رگرسیون خطی شد، ما که کلا مدل را عوض کردیم، دیگر چرا میگوییم رگرسیون خطی؟! ساده هست. به رابطه بالا نگاه کنید. داخل پرانتز تابع سیگموید (wx+b) همان تابع رگرسیون خطی است. یعنی، درواقع ما روی خرووجی رگرسیون خطی یک سیگموید اعمال میکنیم و بعد خروجی نهایی بدست میآید. پس به همین دلیل است که نام رگرسیون را با خود به یدک میکشد. خب حالا ممکن است بپرسید، چرا لجستیک؟ یکم صبر کنید…
اگر بتوانیم مدل جدید را خوب آموزش دهیم، آنگاه میتوانیم انتظار داشته باشیم که براساس دادههای ورودی، تابعی به شکل زیر بهدست بیاید. این مدل آموزش دیده خیلی خوب روی دادههای آموزشی فیت شده است.

تابع اتلاف رگرسیون لجستیک
مدل را ساختیم، اما مساله دیگر این هست که ما تابع اتلافی داریم که برای مساله رگرسیون مناسب هست. چرا MSE برای رگرسیون مناسب هست؟ چون در رگرسیون خطی، مدل میگفت با این داده Xi، من خروجی را 1.2 پیشبینی کردهام. تابع اتلاف میگفت ببین مدل جان خوب گفتیها ولی کمی بیشتر دقت کن، جواب واقعی 1.223 هست. یعنی اختلاف بین مقدار پیشبینی و واقعی مهم بود. اما تابع اتلاف در دسته بندی یا همین رگرسیون لجستیک متفاوت است. مدل میگوید من با داده Xi پیشبینی کردهام که این مدل متعلق به کلاس 0 است. تابع اتلاف باید بگوید بله درست گفتهای. دیگر محاسبه فاصله و اختلاف بین خروجی پیشبینی و واقعی کاربردی ندارد.
همانطور که پیش از این گفتم، در دسته بندی معمولا از تابع اتلاف کراس آنتروپی استفاده میشود.
کراس آنتروپی
تابع اتلاف کراس آنتروپی به صورت زیر تعریف میشود:

ما یک تابع دو ضابطهای داریم که میگوید:
- اگر لیبل واقعی یک داده 1 هست (yt=1)، از ضابطه logyp– استفاده کن.
- اگر هم صفر هست (yt=0) از ضابطه پایینی log1-yp–
به راحتی میتوانیم این تابع دو ضابطهای را یکپارچه کرده و به شکل زیر بنویسیم:
![]()
مگر در X فقط یک نمونه داریم؟ طبیعتا N نمونه داریم. پس قاعدتا باید اتلاف تکتکشان را حساب کنیم و بعد میانگین بگیریم. خب، میانگین اتلاف L به شکل زیر محاسبه میشود:

رابطه بالا را تابع اتلاف کراس آنتروپی مینامیم. واجب است که این فرمول را حفظ کنید.
نکته به تابع اتلاف کراس آنتروپی، Logarithmic Loss یا Log Loss یا Logistic Loss هم گفته میشود. حالا دلیل کلمه لجستیک را در رگرسیون لجستیک متوجه شدید؟
تذکر اسم واقعی رابطه بالا، باینری کراس آنتروپی است. باینری یعنی اینکه این فرمول برای حالتی است که تنها دو کلاس داریم. برای حالت دو کلاس به بالا (چندکلاسه) تغییرات ریزی دارد که فعلا نیازی نیست بدانید. چون رگرسیون لجستیک ذاتا دوکلاسه است.
اگر میخواهید بیشتر از کراس آنتروپی بدانید، بخش بعدی را مطالعه کنید. فعلا آنچه اهمیت دارد این است که فرمول کراس آنتروپی و نحوه استفاده از آن را بدانید.
از کراس آنتروپی بیشتر بدانید!
تابع اتلاف کراس آنتروپی براساس مفهوم مهم آنتروپی در تئوری اطلاعات ساخته شده است. بیایید از نگاه تئوری اطلاعات، ببینیم آنتروپی یعنی چه:
آنتروپیِ یک متغیر تصادفی، میانگین “اطلاعات” یا “عدم قطعیت” پیشامدهای ممکنِ متغیر است.
سخت بود؟ سادهاش این است که هرچه عدم قطعیت یا اطلاعات بیشتر باشد، آنتروپی بالاتر است. یعنی:
- جمله “زمین گرد است” نسبت به “در مریخ آب کشف شده” اطلاعات کمتری دارد و بنابراین آنتروپی کمتری هم دارد.
- پیشبینی بازی “استقلال-پرسپولیس” نسبت به بازی “استقلال-تیم دسته دوم” عدم قعطیت بیشتری دارد (حدس زدنش سختتر است) و بنابراین آنتروپی بالاتری هم دارد.
در تعریف بالا گفتیم، آنتروپی برابراست با میانگین “اطلاعات”. خب پس باید مقدار اطلاعات را به شکل کمی داشته باشیم و بعد از آن میانگین بگیریم که آنتروپی بهدست بیاید. طبق تعریف شانون، اطلاعات یا Information از رابطه زیر بهدست میآید:
![]()
p(x) به احتمال رخداد متغیر x اشاره دارد. به این دو گزاره دقت کنید:
- هرچه عدم قطعیت بیشتر، آنتروپی بالاتر
- آنتروپی بالاتر معادل است با اطلاعات بالاتر
قبول دارید که از دو گزاره بالا میتوان نتیجه گرفت که عدم قطعیت بیشتر یعنی همان اطلاعات بیشتر؟ نمودار زیر نشان میدهد که با افزایش احتمال (رفتن به سمت قطعیت بیشتر)، طبق رابطه بالا اطلاعات کمتر و کمتر میشود:

حالا آنتروپی چه بود؟ میانگین اطلاعات؛ آنتروپی با رابطه زیر محاسبه میشود:

یعنی آنتروپی برابر است با امید ریاضی اطلاعات. در رابطه بالا، E همان امید ریاضی یا Expected Value است. در واقع، یک میانگین وزندار…
نکته منفی در رابطههای بالا برای چیست؟ ببینید، لگاریتم با ورودی 0 تا 1 خروجی منفی میدهد. پس یک منفی گذاشتهایم تا خروجی منفی نباشد. همین!
ارتباط بین آنتروپی و کراس آنتروپی
اکی تعریف آنتروپی و کارکردش را متوجه شدیم، اما چرا باید تابع اتلاف ما در دسته بندی براساس آنتروپی باشد؟ ساده هست؛ خروجی دسته بندی ما احتمالاتی است. یک عدد بین 0 تا 1 است که احتمال کلاس 0 یا 1 بودن را نشان میدهد. وقتی احتمالاتی است یعنی عدم قطعیت هم مطرح هست. حالا حالتهای زیر ممکن است برای مدل پیش بیایید:
- داده ورودی متعلق به کلاس 1 باشد و مدل در خروجی احتمال 0.95 داده است. هیچی دیگر، قطعیت بالاست و درنتیجه آنتروپی بسیار کم است. log0.95=0.05-
- داده متعلق به کلاس 1 و خروجی پیشبینی 0.51 است. عدم قطعیت نسبتا بالاست و درنتیجه آنتروپی هم زیاد میشود. یعنی اتلاف، هزینه یا لاس بالاست. log0.51=0.67-
- برچسب داده 0 و خروجی پیشبینی 0.1 هست. بازهم قطعیت بالا و آنتروپی کم است. log1-0.1=0.1-
میبینید؟ استفاده از کراس آنتروپی برای کار دسته بندی دو/چند کلاسه با خروجی احتمالی منطقی است.
فقط میماند یک سوال که چرا تابع ما دوضابطهاست، درحالیکه آنتروپی تکضابطهای است؟ برای اینکه ما دو کلاس داریم. باید آنتروپی هر کلاس را بهصورت جداگانه حساب کنیم. اگر من تکضابطهای بهکار ببرم، دیگر چگونه آنتروپی یک داده با تارگت 0 و خروجی 0.1 را حساب کنم؟ با تکضابطه که نمیشود این کار را انجام داد.
بسیارخب، ما مدل رگرسیون لجستیک و تابع اتلاف کراس آنتروپی را معرفی کردیم. حالا میماند چارچوب آموزش مدل رگرسیون لجستیک…
بلوک دیاگرام مدل رگرسیون لجستیک
چارچوب آموزش شبکه ما کامل شد. میبینید که همان بلوک دیاگرام رگرسیون خطی است، ولی در بعضی از بلوکها تغییراتی ایجاد کردهایم.

خب به پایان جلسه رگرسیون لجستیک رسیدیم. سعی کردم همه بخشها را شفاف و ساده توضیح بدهم. اما ممکن است به چند بار مطالعه نیاز داشته باشد. همانطور که من مثلا برای نوشتن کراس آنتروپی زمان زیادی گذاشتم تا جستجو، مطالعه و فکر کنم تا به شکلی مناسب آن را توضیح دهم. منتظر کامنتهای شما میمانم تا ببینم در انتقال مطالب موفق بودهام یا نه! من هم بروم سراغ سایر کارهای هوسم. با هوسم همراه باشید…
مطالب زیر را حتما مطالعه کنید
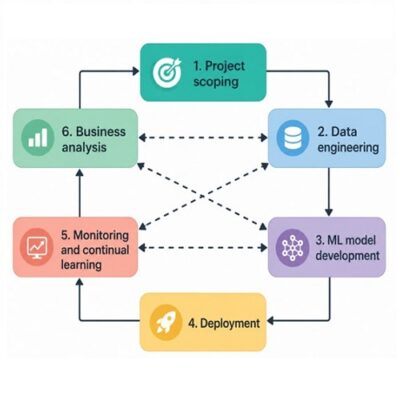
چرخه حیات یادگیری ماشین (ML Lifecycle)

یادگیری ماشین بدون ریاضی و کدنویسی

پیشنیازهای یادگیری ماشین

یادگیری ماشین چیست
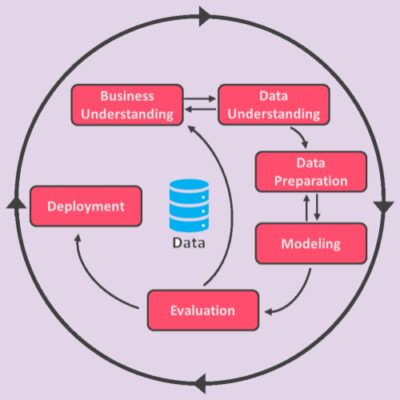
فرآیند کریسپ (CRISP)

آموزش سایکیت لرن
42 دیدگاه
به گفتگوی ما بپیوندید و دیدگاه خود را با ما در میان بگذارید.
سلام،
خیلی خیلی عالیه! واقعا خسته نباشید میگم بهتون برای محتوای ارزشمندی که ایجاد کردید.
فقط یک جای مطلب اشتباه تایپی پیش امده که من اینجا مینویسم بررسی کنید اگر امکانش هست برطرف کنید.
” داده متعلق به کلاس 1 و خروجی پیشبینی 0.51 است. عدم قطعیت نسبتا بالاست و درنتیجه آنتروپی هم زیاد میشود. یعنی اتلاف، هزینه یا لاس بالاست. log(0.51) = 0.67 <—————– " -log0.95=0.67-
با سپاس
سلام
از اینکه آموزش رو دوست داشتید، خوشحالیم.
بله، حق با شماست، اصلاح شد.
ممنون 🌹
من دارم برای پیش دفاع دکترای برق مخابرات خودم رو آماده میکنم و خیلی وقته مطالب شما رو میخونم و کلی پیشرفت کردم توی درک و فهم ماشین لرنینگ و دیپ لرنینگ.لطفا مثال وتمرین های رو هم بیارید که بتونیم از این فرمول ها استفاده کنیم.
سلام
خوشحالیم که آموزشها باعث پیشرفت شما شده.
درحال، مرور و آپدیت محتواهای یادگیری ماشین و یادگیری عمیق هستیم. برنامه داریم که مثال و کدنویسی هم اضافه کنیم.
آرزوی موفقیت برای شما در مقطع دکترا داریم.
سپاسگزاری میکنم به خاطر گرداوری این مطالب بسیار مفید🌷🌼
ممنون 🙏
سلام ممنون بابت زحمتی که کشیدید
یه سوال
اینکه مگه چیدمان ورودی خروجیهای ما همیشه بصورت پله ای هستن که ما بطور قطع میگیم باید از تابع سیگموید برای تخمین تابع روی این نقاط استفاده کنیم. حالا اگه به یه صورت دیگه ای بودن باز هم از تابع سیگموید برای تخمین استفاده میکردیم؟
سلام
ما در مساله طبقه بندی دو کلاسه خطی هستیم. با این فرض، همواره دادههای ما به شکلی قرار گرفتن که بهصورت پلهای میشن. اما طبیعتا، ممکن هست در یک مسالهای دادههای ما آرایش دیگهای داشته باشن که پلهای نباشه و خب دیگه نمیتونیم به این شکل طبقه بندی کنیم و باید دنبال راه حلهای دیگهای باشیم.
سلام وقتتون بخیر
ممنون از مطالب شیوا و عالی توون.
با اینکه انتظار مطالب سنگین و گنگ داشتم همه رو فهمیدم.
البته من دنبال مرز تصمیم بودم و نحوه محاسبش که پیدا نشد :))))
سلام
خوشحالیم که آموزش رو دوست داشتید. 🙏
پیدا کردن مرز تصمیم سخت نیست؛ کافی هست عبارت sigmoid(wx+b)=0.5 یا wx+b=0 رو حل کنید. مقدار w و b رو که دارید. بنابراین، به راحتی میتونید به x روی مرز تصمیم برسید.
چتجیپیتی هم میتونه کمکتون کنه.
یک کتابخونه بنام mlxtend هم داریم که میتونه ناحیه و مرز تصمیم رو براتون رسم کنه.
در فصل رگرسیون لجستیک دوره یادگیری ماشین جامع هوسم هم پیدا کردن مرز تصمیم آموزش داده شده.
موفق باشید 🌹
سلام کاملا معلوم هست که چقدر براش زحمت کشده شده بیخود نتیجه ی اول جستجوی گوگل نشدید
سلام
سپاس 🌹
ممنون از اینکه نظرتون رو کامنت کردید. 😊
درود برای انتروپی، استادمون یه نمونه برامون گفتن که: “فرض کنین این کلاس همه دانشجوهایش به جز یکی، پسر باشند و یکی دختر در کلاس باشد، احتمال اینکه یک پسر از کلاس بیرون بیاید بیشتر از احتمال این است که یک دختر از کلاس بیرون بیاید، پس این کلاس، انتروپی (ناخالصی، ناهمگونی، حالت گرایش به سمت بینظمی) کمتری دارد.
ممنون بابت به اشتراک گذاشتن این مطلب 🌺🙏
سلام وقتتون بخیر.
ممنونم از توضیحات بسیار خوب و شیوایی که داشتین. به زبان ساده خیلی خوب بیان کردید.
میشه لطفا معادل انگلیسیشون هم بنویسید چون مثلا من تابع اتلاف نمیدونم چیه اگر لطف کنید و معادل های انگلیسیشونم بذارید ممنون میشم
سلام 🌹
خوشحالیم که از آموزش راضی بودید.
بله، حتما سعی میکنیم معادل انگلیسی رو هم اضافه کنیم. 😊🙏
آموزش در حد لالیگا. دمتون گرم
ممنون 😊🌹
بسيار عالي، شيوا و كاربردي
سپاس 🌹🙏
سلام
هر مطلبی که میخونم با تمام وجودم شکر گذار خداوند هستم به خاطر وجود افرادی شما که به فکر آموزش دیگران با چنین زبان شیوایی هستید
سلام نازنین عزیز 🌹
ممنون از نظر لطف شما 😊
خیلی ممنونم بابت آموزشهای خیلی کاربردی و شیوا. یه سؤال! من این بخش و متوجه نشدم.
چرا تابع ما دوضابطهاست، درحالیکه آنتروپی تکضابطهای است؟ برای اینکه ما دو کلاس داریم. باید آنتروپی هر کلاس را بهصورت جداگانه حساب کنیم. اگر من تکضابطهای بهکار ببرم، دیگر چگونه آنتروپی یک داده با تارگت 0 و خروجی 0.1 را حساب کنم؟ با تکضابطه که نمیشود این کار را انجام داد.
سلام
تابع تک ضابطهای سَرِهم شده تابع دوضابطهای هست. مثلا در تابع دوضابطهای، اگر y=0 باشه، یکی از ضابطهها اجرا میشه، در تابع تکضابطهای هم اگر y=0 باشه، فقط یکی از اون دو عبارت جمع فعال میشه و اون یکی غیرفعال (صفر) میشه. با گذاشتن دو عبارت y و y-1 عملا یک کلید on/off داریم که مثل دوضابطهای عمل میکنه.